This documentation is for an unreleased version of Apache Flink. We recommend you use the latest stable version.
Elastic Scaling
Elastic Scaling #
Historically, the parallelism of a job has been static throughout its lifecycle and defined once during its submission. Batch jobs couldn’t be rescaled at all, while Streaming jobs could have been stopped with a savepoint and restarted with a different parallelism.
This page describes a new class of schedulers that allow Flink to adjust job’s parallelism at runtime, which pushes Flink one step closer to a truly cloud-native stream processor. The new schedulers are Adaptive Scheduler (streaming) and Adaptive Batch Scheduler (batch).
Adaptive Scheduler #
The Adaptive Scheduler can adjust the parallelism of a job based on available slots. It will automatically reduce the parallelism if not enough slots are available to run the job with the originally configured parallelism; be it due to not enough resources being available at the time of submission, or TaskManager outages during the job execution. If new slots become available the job will be scaled up again, up to the configured parallelism.
In Reactive Mode (see below) the configured parallelism is ignored and treated as if it was set to infinity, letting the job always use as many resources as possible.
One benefit of the Adaptive Scheduler over the default scheduler is that it can handle TaskManager losses gracefully, since it would just scale down in these cases.

Adaptive Scheduler builds on top of a feature called Declarative Resource Management. As you can see, instead of asking for the exact number of slots, JobMaster declares its desired resources (for reactive mode the maximum is set to infinity) to the ResourceManager, which then tries to fulfill those resources.
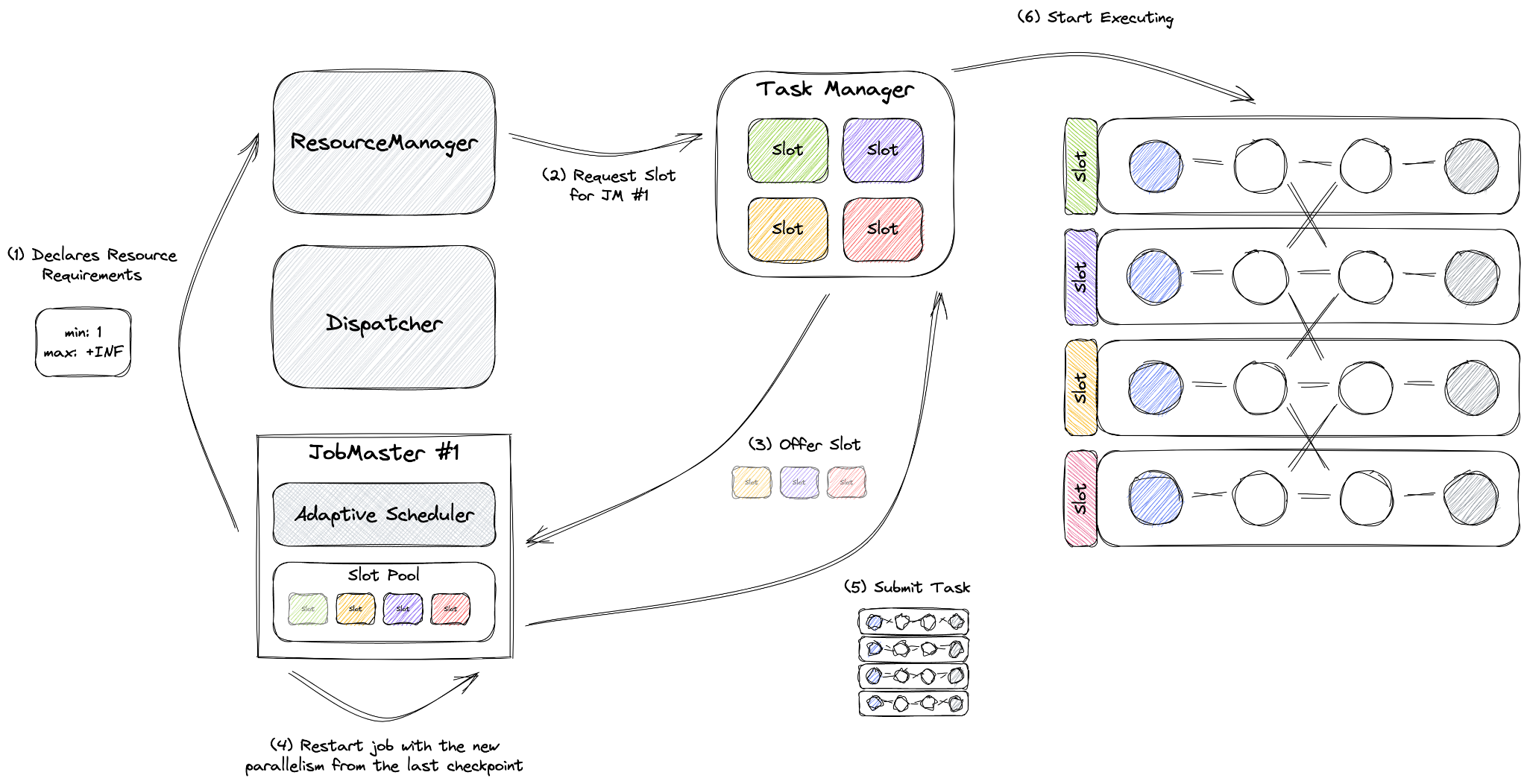
When JobMaster gets more resources during the runtime, it will automatically rescale the job using the latest available savepoint, eliminating the need for an external orchestration.
Starting from Flink 1.18.x, you can re-declare the resource requirements of a running job using Externalized Declarative Resource Management, otherwise the Adaptive Scheduler won’t be able to handle cases where the job needs to be rescaled due to a change in the input rate, or a change in the performance of the workload.
Externalized Declarative Resource Management #
Externalized Declarative Resource Management is an MVP (“minimum viable product”) feature. The Flink community is actively looking for feedback by users through our mailing lists. Please check the limitations listed on this page.
You can use Externalized Declarative Resource Management with the Apache Flink Kubernetes operator for a fully-fledged auto-scaling experience.
Externalized Declarative Resource Management aims to address two deployment scenarios:
- Adaptive Scheduler on Session Cluster, where multiple jobs can compete for resources, and you need a finer-grained control over the distribution of resources between jobs.
- Adaptive Scheduler on Application Cluster in combination with Active Resource Manager (e.g. Native Kubernetes), where you rely on Flink to “greedily” spawn new TaskManagers, but you still want to leverage rescaling capabilities as with Reactive Mode.
by introducing a new REST API endpoint, that allows you to re-declare resource requirements of a running job, by setting per-vertex parallelism boundaries.
PUT /jobs/<job-id>/resource-requirements
REQUEST BODY:
{
"<first-vertex-id>": {
"parallelism": {
"lowerBound": 3,
"upperBound": 5
}
},
"<second-vertex-id>": {
"parallelism": {
"lowerBound": 2,
"upperBound": 3
}
}
}
To a certain extent, the above endpoint could be thought about as a “re-scaling endpoint” and it introduces an important building block for building an auto-scaling experience for Flink.
You can manually try this feature out, by navigating the Job overview in the Flink UI and using up-scale/down-scale buttons in the task list.
Usage #
If you are using Adaptive Scheduler on a session cluster, there are no guarantees regarding the distribution of slots between multiple running jobs in the same session, in case the cluster doesn’t have enough resources. The External Declarative Resource Management can partially mitigate this issue, but it is still recommended to use Adaptive Scheduler on a application cluster.
The jobmanager.scheduler needs to be set to on the cluster level for the adaptive scheduler to be used instead of default scheduler.
jobmanager.scheduler: adaptive
The behavior of Adaptive Scheduler is configured by all configuration options prefixed with jobmanager.adaptive-scheduler in their name.
Limitations #
- Streaming jobs only: The Adaptive Scheduler runs with streaming jobs only. When submitting a batch job, Flink will use the default scheduler of batch jobs, i.e. Adaptive Batch Scheduler
- No support for partial failover: Partial failover means that the scheduler is able to restart parts (“regions” in Flink’s internals) of a failed job, instead of the entire job. This limitation impacts only recovery time of embarrassingly parallel jobs: Flink’s default scheduler can restart failed parts, while Adaptive Scheduler will restart the entire job.
- Scaling events trigger job and task restarts, which will increase the number of Task attempts.
Reactive Mode #
Reactive Mode is a special mode for Adaptive Scheduler, that assumes a single job per-cluster (enforced by the Application Mode). Reactive Mode configures a job so that it always uses all resources available in the cluster. Adding a TaskManager will scale up your job, removing resources will scale it down. Flink will manage the parallelism of the job, always setting it to the highest possible values.
Reactive Mode restarts a job on a rescaling event, restoring it from the latest completed checkpoint. This means that there is no overhead of creating a savepoint (which is needed for manually rescaling a job). Also, the amount of data that is reprocessed after rescaling depends on the checkpointing interval, and the restore time depends on the state size.
The Reactive Mode allows Flink users to implement a powerful autoscaling mechanism, by having an external service monitor certain metrics, such as consumer lag, aggregate CPU utilization, throughput or latency. As soon as these metrics are above or below a certain threshold, additional TaskManagers can be added or removed from the Flink cluster. This could be implemented through changing the replica factor of a Kubernetes deployment, or an autoscaling group on AWS. This external service only needs to handle the resource allocation and deallocation. Flink will take care of keeping the job running with the resources available.
Getting started #
If you just want to try out Reactive Mode, follow these instructions. They assume that you are deploying Flink on a single machine.
# these instructions assume you are in the root directory of a Flink distribution.
# Put Job into lib/ directory
cp ./examples/streaming/TopSpeedWindowing.jar lib/
# Submit Job in Reactive Mode
./bin/standalone-job.sh start -Dscheduler-mode=reactive -Dexecution.checkpointing.interval="10s" -j org.apache.flink.streaming.examples.windowing.TopSpeedWindowing
# Start first TaskManager
./bin/taskmanager.sh start
Let’s quickly examine the used submission command:
./bin/standalone-job.sh startdeploys Flink in Application Mode-Dscheduler-mode=reactiveenables Reactive Mode.-Dexecution.checkpointing.interval="10s"configure checkpointing and restart strategy.- the last argument is passing the Job’s main class name.
You have now started a Flink job in Reactive Mode. The web interface shows that the job is running on one TaskManager. If you want to scale up the job, simply add another TaskManager to the cluster:
# Start additional TaskManager
./bin/taskmanager.sh start
To scale down, remove a TaskManager instance.
# Remove a TaskManager
./bin/taskmanager.sh stop
Usage #
Configuration #
To enable Reactive Mode, you need to configure scheduler-mode to reactive.
The parallelism of individual operators in a job will be determined by the scheduler. It is not configurable and will be ignored if explicitly set, either on individual operators or the entire job.
The only way of influencing the parallelism is by setting a max parallelism for an operator (which will be respected by the scheduler). The maxParallelism is bounded by 2^15 (32768). If you do not set a max parallelism for individual operators or the entire job, the default parallelism rules will be applied, potentially applying lower bounds than the max possible value. As with the default scheduling mode, please take the best practices for parallelism into consideration.
Note that such a high max parallelism might affect performance of the job, since more internal structures are needed to maintain some internal structures of Flink.
When enabling Reactive Mode, the jobmanager.adaptive-scheduler.resource-wait-timeout configuration key will default to -1. This means that the JobManager will run forever waiting for sufficient resources.
If you want the JobManager to stop after a certain time without enough TaskManagers to run the job, configure jobmanager.adaptive-scheduler.resource-wait-timeout.
With Reactive Mode enabled, the jobmanager.adaptive-scheduler.resource-stabilization-timeout configuration key will default to 0: Flink will start running the job, as soon as there are sufficient resources available.
In scenarios where TaskManagers are not connecting at the same time, but slowly one after another, this behavior leads to a job restart whenever a TaskManager connects. Increase this configuration value if you want to wait for the resources to stabilize before scheduling the job.
Additionally, one can configure jobmanager.adaptive-scheduler.min-parallelism-increase: This configuration option specifics the minimum amount of additional, aggregate parallelism increase before triggering a scale-up. For example if you have a job with a source (parallelism=2) and a sink (parallelism=2), the aggregate parallelism is 4. By default, the configuration key is set to 1, so any increase in the aggregate parallelism will trigger a restart.
One can force scaling operations to happen by setting jobmanager.adaptive-scheduler.scaling-interval.max. It is disabled by default. If set, then when new resources are added to the cluster, a rescale is scheduled after jobmanager.adaptive-scheduler.scaling-interval.max even if jobmanager.adaptive-scheduler.min-parallelism-increase is not satisfied.
To avoid too frequent scaling operations, one can configure jobmanager.adaptive-scheduler.scaling-interval.min to set the minimum time between 2 scaling operations. The default is 30s.
Recommendations #
-
Configure periodic checkpointing for stateful jobs: Reactive mode restores from the latest completed checkpoint on a rescale event. If no periodic checkpointing is enabled, your program will lose its state. Checkpointing also configures a restart strategy. Reactive Mode will respect the configured restarting strategy: If no restarting strategy is configured, reactive mode will fail your job, instead of scaling it.
-
Downscaling in Reactive Mode might take longer if the TaskManager is not properly shutdown (i.e., if a SIGKILL signal is used instead of a SIGTERM signal). In this case, Flink waits for the heartbeat between JobManager and the stopped TaskManager(s) to time out. You will see that your Flink job is stuck for roughly 50 seconds before redeploying your job with a lower parallelism.
The default timeout is configured to 50 seconds. Adjust the
heartbeat.timeoutconfiguration to a lower value, if your infrastructure permits this. Setting a low heartbeat timeout can lead to failures if a TaskManager fails to respond to a heartbeat, for example due to a network congestion or a long garbage collection pause. Note that theheartbeat.intervalalways needs to be lower than the timeout.
Limitations #
Since Reactive Mode is a new, experimental feature, not all features supported by the default scheduler are also available with Reactive Mode (and its adaptive scheduler). The Flink community is working on addressing these limitations.
-
Deployment is only supported as a standalone application deployment. Active resource providers (such as native Kubernetes, YARN) are explicitly not supported. Standalone session clusters are not supported either. The application deployment is limited to single job applications.
The only supported deployment options are Standalone in Application Mode (described on this page), Docker in Application Mode and Standalone Kubernetes Application Cluster.
The limitations of Adaptive Scheduler also apply to Reactive Mode.
Adaptive Batch Scheduler #
The Adaptive Batch Scheduler is a batch job scheduler that can automatically adjust the execution plan. It currently supports automatically deciding parallelisms of operators for batch jobs. If an operator is not set with a parallelism, the scheduler will decide parallelism for it according to the size of its consumed datasets. This can bring many benefits:
- Batch job users can be relieved from parallelism tuning
- Automatically tuned parallelisms can better fit consumed datasets which have a varying volume size every day
- Operators from SQL batch jobs can be assigned with different parallelisms which are automatically tuned
At present, the Adaptive Batch Scheduler is the default scheduler for Flink batch jobs. No additional configuration is required unless other schedulers are explicitly configured, e.g. jobmanager.scheduler: default. Note that you need to
leave the execution.batch-shuffle-mode unset or explicitly set it to ALL_EXCHANGES_BLOCKING (default value) or ALL_EXCHANGES_HYBRID_FULL or ALL_EXCHANGES_HYBRID_SELECTIVE due to “BLOCKING or HYBRID jobs only”.
Automatically decide parallelisms for operators #
Usage #
To automatically decide parallelisms for operators with Adaptive Batch Scheduler, you need to:
-
Toggle the feature on:
Adaptive Batch Scheduler enables automatic parallelism derivation by default. You can configure
execution.batch.adaptive.auto-parallelism.enabledto toggle this feature. In addition, there are several related configuration options that may need adjustment when using Adaptive Batch Scheduler to automatically decide parallelisms for operators:execution.batch.adaptive.auto-parallelism.min-parallelism: The lower bound of allowed parallelism to set adaptively.execution.batch.adaptive.auto-parallelism.max-parallelism: The upper bound of allowed parallelism to set adaptively. The default parallelism set viaparallelism.defaultorStreamExecutionEnvironment#setParallelism()will be used as upper bound of allowed parallelism if this configuration is not configured.execution.batch.adaptive.auto-parallelism.avg-data-volume-per-task: The average size of data volume to expect each task instance to process. Note that when data skew occurs, or the decided parallelism reaches the max parallelism (due to too much data), the data actually processed by some tasks may far exceed this value.execution.batch.adaptive.auto-parallelism.default-source-parallelism: The default parallelism of data source or the upper bound of source parallelism to set adaptively. The upper bound of allowed parallelism set viaexecution.batch.adaptive.auto-parallelism.max-parallelismwill be used if this configuration is not configured. If the upper bound of allowed parallelism is also not configured, the default parallelism set viaparallelism.defaultorStreamExecutionEnvironment#setParallelism()will be used instead.
-
Avoid setting the parallelism of operators:
The Adaptive Batch Scheduler only decides the parallelism for operators which do not have a parallelism set. So if you want the parallelism of an operator to be automatically decided, you need to avoid setting the parallelism for the operator through the ‘setParallelism()’ method.
In addition, the following configurations are required for DataSet jobs:
- Set
parallelism.default: -1. - Don’t call
setParallelism()onExecutionEnvironment.
- Set
Enable dynamic parallelism inference support for Sources #
New Source can implement the interface DynamicParallelismInference to enable dynamic parallelism inference.
public interface DynamicParallelismInference {
int inferParallelism(Context context);
}
The Context will provide the upper bound for the inferred parallelism, the expected average data size to be processed by each task, and dynamic filtering information to assist with parallelism inference.
The Adaptive Batch Scheduler will invoke the interface before scheduling the source vertices, and it should be noted that implementations should avoid time-consuming operations as much as possible.
If the Source does not implement the interface, the configuration setting execution.batch.adaptive.auto-parallelism.default-source-parallelism will be used as the parallelism of the source vertices.
Note that the dynamic source parallelism inference only decides the parallelism for source operators which do not already have a specified parallelism.
Performance tuning #
- It’s recommended to use Sort Shuffle and set
taskmanager.network.memory.buffers-per-channelto0. This can decouple the required network memory from parallelism, so that for large scale jobs, the “Insufficient number of network buffers” errors are less likely to happen. - It’s recommended to set
execution.batch.adaptive.auto-parallelism.max-parallelismto the parallelism you expect to need in the worst case. Values larger than that are not recommended, because excessive value may affect the performance. This option can affect the number of subpartitions produced by upstream tasks, large number of subpartitions may degrade the performance of hash shuffle and the performance of network transmission due to small packets.
Limitations #
- Batch jobs only: Adaptive Batch Scheduler only supports batch jobs. Exception will be thrown if a streaming job is submitted.
- BLOCKING or HYBRID jobs only: At the moment, Adaptive Batch Scheduler only supports jobs whose shuffle mode is
ALL_EXCHANGES_BLOCKING / ALL_EXCHANGES_HYBRID_FULL / ALL_EXCHANGES_HYBRID_SELECTIVE. Note that for DataSet jobs which do not recognize the aforementioned shuffle mode, the ExecutionMode needs to be BATCH_FORCED to force BLOCKING shuffle. - FileInputFormat sources are not supported: FileInputFormat sources are not supported, including
StreamExecutionEnvironment#readFile(...)StreamExecutionEnvironment#readTextFile(...)andStreamExecutionEnvironment#createInput(FileInputFormat, ...). Users should use the new sources(FileSystem DataStream Connector or FileSystem SQL Connector) to read files when using the Adaptive Batch Scheduler. - Inconsistent broadcast results metrics on WebUI: When use Adaptive Batch Scheduler to automatically decide parallelisms for operators, for broadcast results, the number of bytes/records sent by the upstream task counted by metric is not equal to the number of bytes/records received by the downstream task, which may confuse users when displayed on the Web UI. See FLIP-187 for details.