Streaming File Sink
这个连接器提供了一个 Sink 来将分区文件写入到支持 Flink FileSystem 接口的文件系统中。
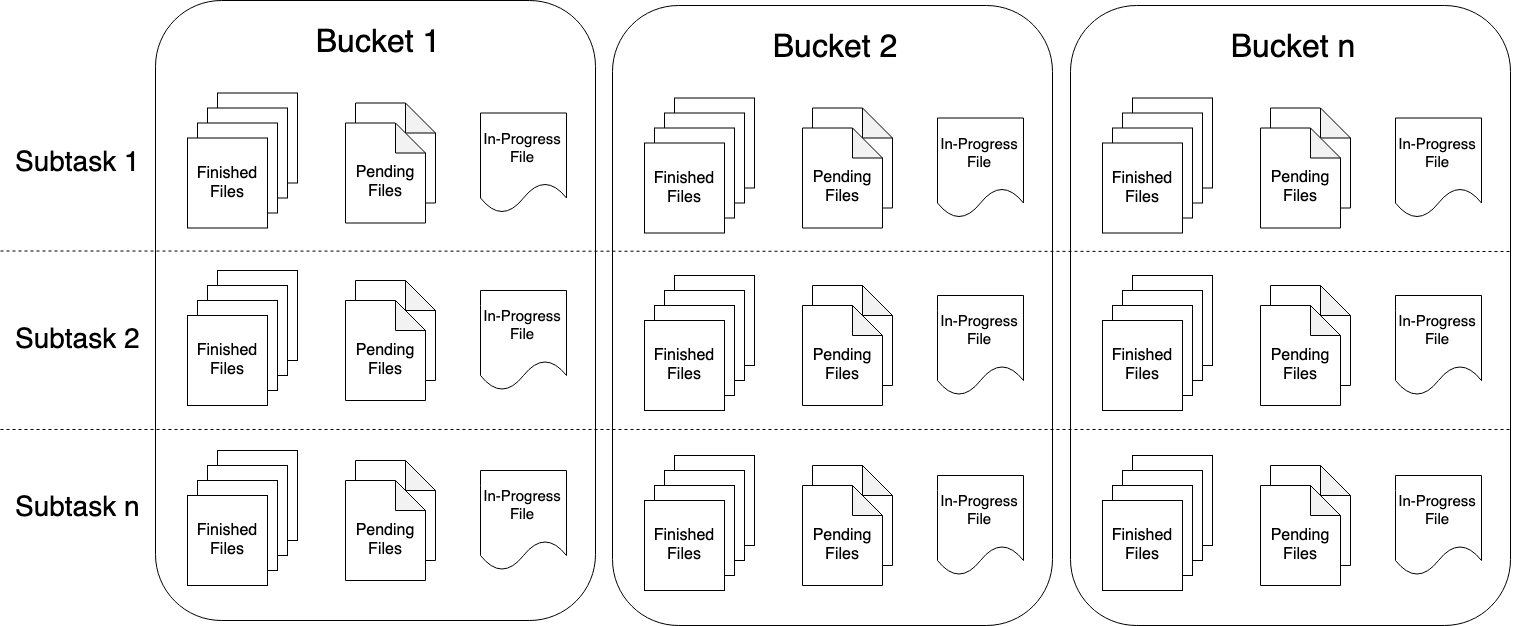
Streaming File Sink 会将数据写入到桶中。由于输入流可能是无界的,因此每个桶中的数据被划分为多个有限大小的文件。如何分桶是可以配置的,默认使用基于时间的分桶策略,这种策略每个小时创建一个新的桶,桶中包含的文件将记录所有该小时内从流中接收到的数据。
桶目录中的实际输出数据会被划分为多个部分文件(part file),每一个接收桶数据的 Sink Subtask ,至少包含一个部分文件(part file)。额外的部分文件(part file)将根据滚动策略创建,滚动策略是可以配置的。默认的策略是根据文件大小和超时时间来滚动文件。超时时间指打开文件的最长持续时间,以及文件关闭前的最长非活动时间。
文件格式
StreamingFileSink 支持行编码格式和批量编码格式,比如 Apache Parquet 。
这两种变体随附了各自的构建器,可以使用以下静态方法创建:
- Row-encoded sink:
StreamingFileSink.forRowFormat(basePath, rowEncoder) - Bulk-encoded sink:
StreamingFileSink.forBulkFormat(basePath, bulkWriterFactory)
创建行或批量编码的 Sink 时,我们需要指定存储桶的基本路径和数据的编码逻辑。
更多配置操作以及不同数据格式的实现请参考 StreamingFileSink
行编码格式
行编码格式需要指定一个 Encoder 。Encoder 负责为每个处于 In-progress 状态文件的OutputStream 序列化数据。
除了桶分配器之外,RowFormatBuilder 还允许用户指定:
- Custom RollingPolicy :自定义滚动策略以覆盖默认的 DefaultRollingPolicy
- bucketCheckInterval (默认为1分钟):毫秒间隔,用于基于时间的滚动策略。
字符串元素写入示例:
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
DataStream<String> input = ...;
final StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build();
input.addSink(sink);import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
val input: DataStream[String] = ...
val sink: StreamingFileSink[String] = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build()
input.addSink(sink)这个例子创建了一个简单的 Sink ,将记录分配给默认的一小时时间桶。它还指定了一个滚动策略,该策略在以下三种情况下滚动处于 In-progress 状态的部分文件(part file):
- 它至少包含 15 分钟的数据
- 最近 5 分钟没有收到新的记录
- 文件大小达到 1GB (写入最后一条记录后)
批量编码格式
批量编码 Sink 的创建与行编码 Sink 相似,不过在这里我们不是指定编码器 Encoder 而是指定 BulkWriter.Factory 。
BulkWriter 定义了如何添加、刷新元素,以及如何批量编码。
Flink 有四个内置的 BulkWriter Factory :
- ParquetWriterFactory
- AvroWriterFactory
- SequenceFileWriterFactory
- CompressWriterFactory
- OrcBulkWriterFactory
Parquet 格式
Flink 包含为不同 Avro 类型,创建 ParquetWriterFactory 的便捷方法,更多信息请参考 ParquetAvroWriters 。
要编写其他 Parquet 兼容的数据格式,用户需要创建 ParquetWriterFactory 并实现 ParquetBuilder 接口。
在应用中使用 Parquet 批量编码器,你需要添加以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.11</artifactId>
<version>1.11.6</version>
</dependency>这个例子使用 StreamingFileSink 将 Avro 数据写入 Parquet 格式:
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters;
import org.apache.avro.Schema;
Schema schema = ...;
DataStream<GenericRecord> stream = ...;
final StreamingFileSink<GenericRecord> sink = StreamingFileSink
.forBulkFormat(outputBasePath, ParquetAvroWriters.forGenericRecord(schema))
.build();
input.addSink(sink);import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters
import org.apache.avro.Schema
val schema: Schema = ...
val input: DataStream[GenericRecord] = ...
val sink: StreamingFileSink[GenericRecord] = StreamingFileSink
.forBulkFormat(outputBasePath, ParquetAvroWriters.forGenericRecord(schema))
.build()
input.addSink(sink)Avro格式
Flink 也提供了将数据写入 Avro 文件的内置支持。对于创建 AvroWriterFactory 的快捷方法,更多信息可以参考 AvroWriters.
使用Avro相关的Writer需要在项目中添加以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>1.11.6</version>
</dependency>将数据写入 Avro 文件的 StreamingFileSink 算子可以通过如下方式创建:
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.formats.avro.AvroWriters;
import org.apache.avro.Schema;
Schema schema = ...;
DataStream<GenericRecord> stream = ...;
final StreamingFileSink<GenericRecord> sink = StreamingFileSink
.forBulkFormat(outputBasePath, AvroWriters.forGenericRecord(schema))
.build();
input.addSink(sink);import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.formats.avro.AvroWriters
import org.apache.avro.Schema
val schema: Schema = ...
val input: DataStream[GenericRecord] = ...
val sink: StreamingFileSink[GenericRecord] = StreamingFileSink
.forBulkFormat(outputBasePath, AvroWriters.forGenericRecord(schema))
.build()
input.addSink(sink)如果想要创建自定义的 Avro Writer,例如启用压缩等,用户可以实现 AvroBuilder
接口并自行创建一个 AvroWriterFactory 实例:
AvroWriterFactory<?> factory = new AvroWriterFactory<>((AvroBuilder<Address>) out -> {
Schema schema = ReflectData.get().getSchema(Address.class);
DatumWriter<Address> datumWriter = new ReflectDatumWriter<>(schema);
DataFileWriter<Address> dataFileWriter = new DataFileWriter<>(datumWriter);
dataFileWriter.setCodec(CodecFactory.snappyCodec());
dataFileWriter.create(schema, out);
return dataFileWriter;
});
DataStream<Address> stream = ...
stream.addSink(StreamingFileSink.forBulkFormat(
outputBasePath,
factory).build());val factory = new AvroWriterFactory[Address](new AvroBuilder[Address]() {
override def createWriter(out: OutputStream): DataFileWriter[Address] = {
val schema = ReflectData.get.getSchema(classOf[Address])
val datumWriter = new ReflectDatumWriter[Address](schema)
val dataFileWriter = new DataFileWriter[Address](datumWriter)
dataFileWriter.setCodec(CodecFactory.snappyCodec)
dataFileWriter.create(schema, out)
dataFileWriter
}
})
val stream: DataStream[Address] = ...
stream.addSink(StreamingFileSink.forBulkFormat(
outputBasePath,
factory).build());ORC Format
To enable the data to be bulk encoded in ORC format, Flink offers OrcBulkWriterFactory which takes a concrete implementation of Vectorizer.
Like any other columnar format that encodes data in bulk fashion, Flink’s OrcBulkWriter writes the input elements in batches. It uses
ORC’s VectorizedRowBatch to achieve this.
Since the input element has to be transformed to a VectorizedRowBatch, users have to extend the abstract Vectorizer
class and override the vectorize(T element, VectorizedRowBatch batch) method. As you can see, the method provides an
instance of VectorizedRowBatch to be used directly by the users so users just have to write the logic to transform the
input element to ColumnVectors and set them in the provided VectorizedRowBatch instance.
For example, if the input element is of type Person which looks like:
class Person {
private final String name;
private final int age;
...
}Then a child implementation to convert the element of type Person and set them in the VectorizedRowBatch can be like:
import org.apache.hadoop.hive.ql.exec.vector.BytesColumnVector;
import org.apache.hadoop.hive.ql.exec.vector.LongColumnVector;
import java.io.IOException;
import java.io.Serializable;
import java.nio.charset.StandardCharsets;
public class PersonVectorizer extends Vectorizer<Person> implements Serializable {
public PersonVectorizer(String schema) {
super(schema);
}
@Override
public void vectorize(Person element, VectorizedRowBatch batch) throws IOException {
BytesColumnVector nameColVector = (BytesColumnVector) batch.cols[0];
LongColumnVector ageColVector = (LongColumnVector) batch.cols[1];
int row = batch.size++;
nameColVector.setVal(row, element.getName().getBytes(StandardCharsets.UTF_8));
ageColVector.vector[row] = element.getAge();
}
}import java.nio.charset.StandardCharsets
import org.apache.hadoop.hive.ql.exec.vector.{BytesColumnVector, LongColumnVector}
class PersonVectorizer(schema: String) extends Vectorizer[Person](schema) {
override def vectorize(element: Person, batch: VectorizedRowBatch): Unit = {
val nameColVector = batch.cols(0).asInstanceOf[BytesColumnVector]
val ageColVector = batch.cols(1).asInstanceOf[LongColumnVector]
nameColVector.setVal(batch.size + 1, element.getName.getBytes(StandardCharsets.UTF_8))
ageColVector.vector(batch.size + 1) = element.getAge
}
}To use the ORC bulk encoder in an application, users need to add the following dependency:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-orc_2.11</artifactId>
<version>1.11.6</version>
</dependency>And then a StreamingFileSink that writes data in ORC format can be created like this:
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.orc.writer.OrcBulkWriterFactory;
String schema = "struct<_col0:string,_col1:int>";
DataStream<Person> stream = ...;
final OrcBulkWriterFactory<Person> writerFactory = new OrcBulkWriterFactory<>(new PersonVectorizer(schema));
final StreamingFileSink<Person> sink = StreamingFileSink
.forBulkFormat(outputBasePath, writerFactory)
.build();
input.addSink(sink);import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.orc.writer.OrcBulkWriterFactory
val schema: String = "struct<_col0:string,_col1:int>"
val input: DataStream[Person] = ...
val writerFactory = new OrcBulkWriterFactory(new PersonVectorizer(schema));
val sink: StreamingFileSink[Person] = StreamingFileSink
.forBulkFormat(outputBasePath, writerFactory)
.build()
input.addSink(sink)OrcBulkWriterFactory can also take Hadoop Configuration and Properties so that a custom Hadoop configuration and ORC
writer properties can be provided.
String schema = ...;
Configuration conf = ...;
Properties writerProperties = new Properties();
writerProps.setProperty("orc.compress", "LZ4");
// Other ORC supported properties can also be set similarly.
final OrcBulkWriterFactory<Person> writerFactory = new OrcBulkWriterFactory<>(
new PersonVectorizer(schema), writerProperties, conf);val schema: String = ...
val conf: Configuration = ...
val writerProperties: Properties = new Properties()
writerProps.setProperty("orc.compress", "LZ4")
// Other ORC supported properties can also be set similarly.
val writerFactory = new OrcBulkWriterFactory(
new PersonVectorizer(schema), writerProperties, conf)The complete list of ORC writer properties can be found here.
Users who want to add user metadata to the ORC files can do so by calling addUserMetadata(...) inside the overriding
vectorize(...) method.
public class PersonVectorizer extends Vectorizer<Person> implements Serializable {
@Override
public void vectorize(Person element, VectorizedRowBatch batch) throws IOException {
...
String metadataKey = ...;
ByteBuffer metadataValue = ...;
this.addUserMetadata(metadataKey, metadataValue);
}
}class PersonVectorizer(schema: String) extends Vectorizer[Person](schema) {
override def vectorize(element: Person, batch: VectorizedRowBatch): Unit = {
...
val metadataKey: String = ...
val metadataValue: ByteBuffer = ...
addUserMetadata(metadataKey, metadataValue)
}
}Hadoop SequenceFile 格式
在应用中使用 SequenceFile 批量编码器,你需要添加以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sequence-file</artifactId>
<version>1.11.6</version>
</dependency>简单的 SequenceFile 写入示例:
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.configuration.GlobalConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
DataStream<Tuple2<LongWritable, Text>> input = ...;
Configuration hadoopConf = HadoopUtils.getHadoopConfiguration(GlobalConfiguration.loadConfiguration());
final StreamingFileSink<Tuple2<LongWritable, Text>> sink = StreamingFileSink
.forBulkFormat(
outputBasePath,
new SequenceFileWriterFactory<>(hadoopConf, LongWritable.class, Text.class))
.build();
input.addSink(sink);import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.configuration.GlobalConfiguration
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.io.SequenceFile
import org.apache.hadoop.io.Text;
val input: DataStream[(LongWritable, Text)] = ...
val hadoopConf: Configuration = HadoopUtils.getHadoopConfiguration(GlobalConfiguration.loadConfiguration())
val sink: StreamingFileSink[(LongWritable, Text)] = StreamingFileSink
.forBulkFormat(
outputBasePath,
new SequenceFileWriterFactory(hadoopConf, LongWritable.class, Text.class))
.build()
input.addSink(sink)SequenceFileWriterFactory 支持附加构造函数参数指定压缩设置。
桶分配
桶分配逻辑定义了如何将数据结构化为基本输出目录中的子目录
行格式和批量格式都使用 DateTimeBucketAssigner 作为默认的分配器。
默认情况下,DateTimeBucketAssigner 基于系统默认时区每小时创建一个桶,格式如下: yyyy-MM-dd--HH 。日期格式(即桶的大小)和时区都可以手动配置。
我们可以在格式构建器上调用 .withBucketAssigner(assigner) 来自定义 BucketAssigner 。
Flink 有两个内置的 BucketAssigners :
- DateTimeBucketAssigner :默认基于时间的分配器
- BasePathBucketAssigner :将所有部分文件(part file)存储在基本路径中的分配器(单个全局桶)
滚动策略
滚动策略 RollingPolicy 定义了指定的文件在何时关闭(closed)并将其变为 Pending 状态,随后变为 Finished 状态。处于 Pending 状态的文件会在下一次 Checkpoint 时变为 Finished 状态,通过设置 Checkpoint 间隔时间,可以控制部分文件(part file)对下游读取者可用的速度、大小和数量。
Flink 有两个内置的滚动策略:
部分文件(part file) 生命周期
为了在下游系统中使用 StreamingFileSink 的输出,我们需要了解输出文件的命名规则和生命周期。
部分文件(part file)可以处于以下三种状态之一:
- In-progress :当前文件正在写入中
- Pending :当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态
- Finished :在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态
处于 Finished 状态的文件不会再被修改,可以被下游系统安全地读取。
对于每个活动的桶,Writer 在任何时候都只有一个处于 In-progress 状态的部分文件(part file),但是可能有几个 Penging 和 Finished 状态的部分文件(part file)。
部分文件(part file)例子
为了更好地理解这些文件的生命周期,让我们来看一个包含 2 个 Sink Subtask 的简单例子:
└── 2019-08-25--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
└── part-1-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
当部分文件 part-1-0 被滚动(假设它变得太大了)时,它将成为 Pending 状态,但是它还没有被重命名。然后 Sink 会创建一个新的部分文件: part-1-1:
└── 2019-08-25--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
part-1-0 现在处于 Pending 状态等待完成,在下一次成功的 Checkpoint 后,它会变成 Finished 状态:
└── 2019-08-25--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
根据分桶策略创建新的桶,但是这并不会影响当前处于 In-progress 状态的文件:
└── 2019-08-25--12
├── part-0-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-1-0
└── part-1-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
└── 2019-08-25--13
└── part-0-2.inprogress.2b475fec-1482-4dea-9946-eb4353b475f1
因为分桶策略基于每条记录进行评估,所以旧桶仍然可以接受新的记录。
部分文件的配置项
已经完成的文件和进行中的文件仅能通过文件名格式进行区分。
默认情况下,文件命名格式如下所示:
- In-progress / Pending:
part-<subtaskIndex>-<partFileIndex>.inprogress.uid - FINISHED:
part-<subtaskIndex>-<partFileIndex>
Flink 允许用户通过 OutputFileConfig 指定部分文件名的前缀和后缀。
举例来说,前缀设置为 “prefix” 以及后缀设置为 “.ext” 之后,Sink 创建的文件名如下所示:
└── 2019-08-25--12
├── prefix-0-0.ext
├── prefix-0-1.ext.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── prefix-1-0.ext
└── prefix-1-1.ext.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
用户可以通过如下方式设置 OutputFileConfig:
OutputFileConfig config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build();
StreamingFileSink<Tuple2<Integer, Integer>> sink = StreamingFileSink
.forRowFormat((new Path(outputPath), new SimpleStringEncoder<>("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build();val config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build()
val sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build()重要注意事项
通用注意事项
重要提示 1: 使用 Hadoop < 2.7 时,请使用 OnCheckpointRollingPolicy 滚动策略,该策略会在每次检查点时进行文件切割。
这样做的原因是如果部分文件的生命周期跨多个检查点,当 StreamingFileSink 从之前的检查点进行恢复时会调用文件系统的 truncate() 方法清理 in-progress 文件中未提交的数据。
Hadoop 2.7 之前的版本不支持这个方法,因此 Flink 会报异常。
重要提示 2: 鉴于 Flink 的 sink 以及 UDF 通常不会区分作业的正常结束(比如有限流)和异常终止,因此正常结束作业的最后一批 in-progress 文件不会被转换到 “完成” 状态。
重要提示 3: Flink 以及 StreamingFileSink 不会覆盖已经提交的数据。因此如果尝试从一个包含 in-progress 文件的旧 checkpoint/savepoint 恢复,
且这些 in-progress 文件会被接下来的成功 checkpoint 提交,Flink 会因为无法找到 in-progress 文件而抛异常,从而恢复失败。
重要提示 4: 目前 StreamingFileSink 只支持三种文件系统: HDFS、S3和Local。如果配置了不支持的文件系统,在执行的时候 Flink 会抛出异常。
S3 特有的注意事项
重要提示 1: 对于 S3,StreamingFileSink 只支持基于 Hadoop
的文件系统实现,不支持基于 Presto 的实现。如果想使用 StreamingFileSink 向 S3 写入数据并且将
checkpoint 放在基于 Presto 的文件系统,建议明确指定 “s3a://” (for Hadoop)作为sink的目标路径方案,并且为 checkpoint 路径明确指定 “s3p://” (for Presto)。
如果 Sink 和 checkpoint 都使用 “s3://” 路径的话,可能会导致不可预知的行为,因为双方的实现都在“监听”这个路径。
重要提示 2: StreamingFileSink 使用 S3 的 Multi-part Upload
(后续使用MPU代替)特性可以保证精确一次的语义。这个特性支持以独立的块(因此被称为”multi-part”)模式上传文件,当 MPU 的所有部分文件
成功上传之后,可以合并成原始文件。对于失效的 MPUs,S3 提供了一个基于桶生命周期的规则,用户可以用这个规则来丢弃在指定时间内未完成的MPU。
如果在一些部分文件还未上传时触发 savepoint,并且这个规则设置的比较严格,这意味着相关的 MPU在作业重启之前可能会超时。后续的部分文件没
有写入到 savepoint, 那么在 Flink 作业从 savepoint 恢复时,会因为拿不到缺失的部分文件,导致任务失败并抛出异常。