![]() v1.5
v1.5
SQL Client Beta
Flink’s Table & SQL API makes it possible to work with queries written in the SQL language, but these queries need to be embedded within a table program that is written in either Java or Scala. Moreover, these programs need to be packaged with a build tool before being submitted to a cluster. This more or less limits the usage of Flink to Java/Scala programmers.
The SQL Client aims to provide an easy way of writing, debugging, and submitting table programs to a Flink cluster without a single line of Java or Scala code. The SQL Client CLI allows for retrieving and visualizing real-time results from the running distributed application on the command line.
Attention The SQL Client is in an early development phase. Even though the application is not production-ready yet, it can be a quite useful tool for prototyping and playing around with Flink SQL. In the future, the community plans to extend its functionality by providing a REST-based SQL Client Gateway.
Getting Started
This section describes how to setup and run your first Flink SQL program from the command-line.
The SQL Client is bundled in the regular Flink distribution and thus runnable out-of-the-box. It requires only a running Flink cluster where table programs can be executed. For more information about setting up a Flink cluster see the Cluster & Deployment part. If you simply want to try out the SQL Client, you can also start a local cluster with one worker using the following command:
./bin/start-cluster.shStarting the SQL Client CLI
The SQL Client scripts are also located in the binary directory of Flink. In the future, a user will have two possibilities of starting the SQL Client CLI either by starting an embedded standalone process or by connecting to a remote SQL Client Gateway. At the moment only the embedded mode is supported. You can start the CLI by calling:
./bin/sql-client.sh embeddedBy default, the SQL Client will read its configuration from the environment file located in ./conf/sql-client-defaults.yaml. See the configuration part for more information about the structure of environment files.
Running SQL Queries
Once the CLI has been started, you can use the HELP command to list all available SQL statements. For validating your setup and cluster connection, you can enter your first SQL query and press the Enter key to execute it:
SELECT 'Hello World'This query requires no table source and produces a single row result. The CLI will retrieve results from the cluster and visualize them. You can close the result view by pressing the Q key.
The CLI supports two modes for maintaining and visualizing results.
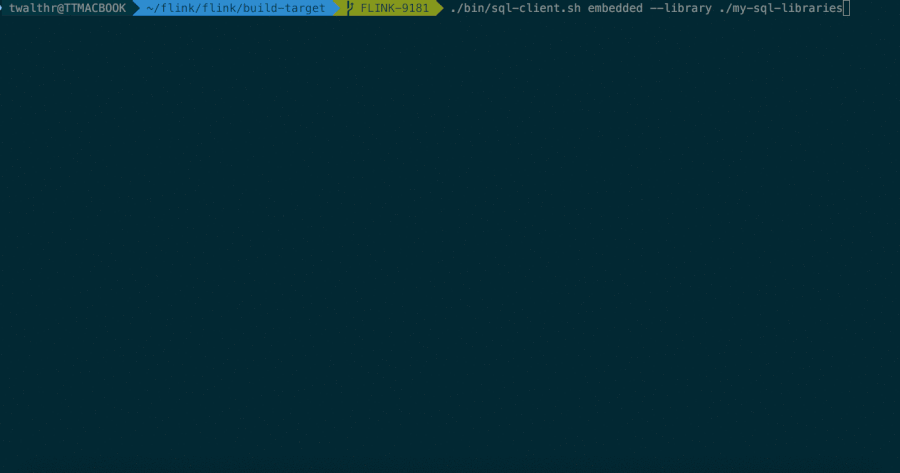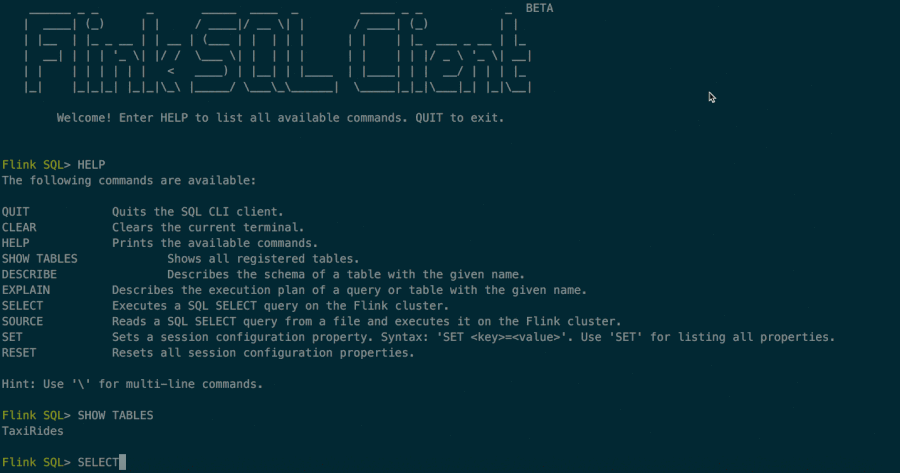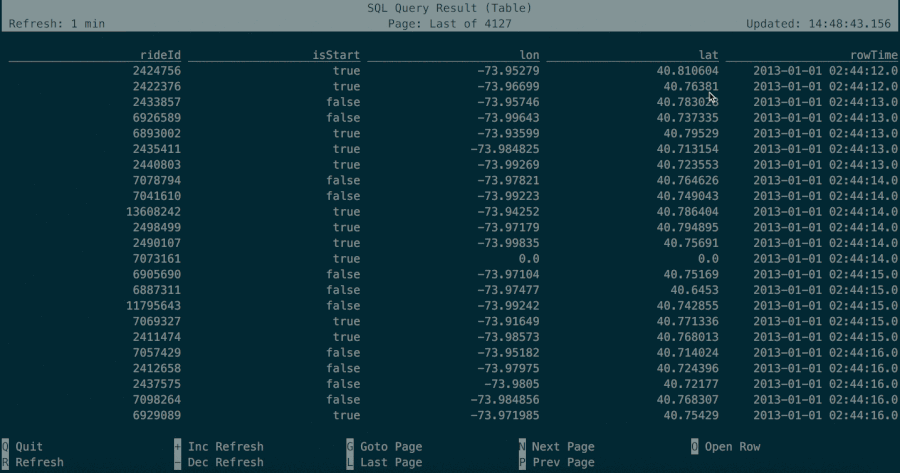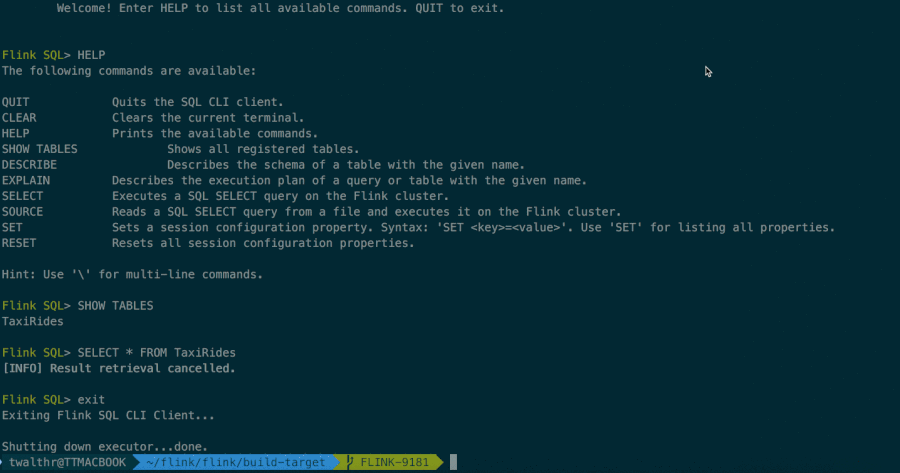
The table mode materializes results in memory and visualizes them in a regular, paginated table representation. It can be enabled by executing the following command in the CLI:
SET execution.result-mode=tableThe changelog mode does not materialize results and visualizes the result stream that is produced by a continuous query consisting of insertions (+) and retractions (-).
SET execution.result-mode=changelogYou can use the following query to see both result modes in action:
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name This query performs a bounded word count example.
In changelog mode, the visualized changelog should be similar to:
+ Bob, 1
+ Alice, 1
+ Greg, 1
- Bob, 1
+ Bob, 2In table mode, the visualized result table is continuously updated until the table program ends with:
Bob, 2
Alice, 1
Greg, 1The configuration section explains how to read from table sources and configure other table program properties.
Configuration
The SQL Client can be started with the following optional CLI commands. They are discussed in detail in the subsequent paragraphs.
./bin/sql-client.sh embedded --help
Mode "embedded" submits Flink jobs from the local machine.
Syntax: embedded [OPTIONS]
"embedded" mode options:
-d,--defaults <environment file> The environment properties with which
every new session is initialized.
Properties might be overwritten by
session properties.
-e,--environment <environment file> The environment properties to be
imported into the session. It might
overwrite default environment
properties.
-h,--help Show the help message with
descriptions of all options.
-j,--jar <JAR file> A JAR file to be imported into the
session. The file might contain
user-defined classes needed for the
execution of statements such as
functions, table sources, or sinks.
Can be used multiple times.
-l,--library <JAR directory> A JAR file directory with which every
new session is initialized. The files
might contain user-defined classes
needed for the execution of
statements such as functions, table
sources, or sinks. Can be used
multiple times.
-s,--session <session identifier> The identifier for a session.
'default' is the default identifier.Environment Files
A SQL query needs a configuration environment in which it is executed. The so-called environment files define available table sources and sinks, external catalogs, user-defined functions, and other properties required for execution and deployment.
Every environment file is a regular YAML file. An example of such a file is presented below.
# Define table sources here.
tables:
- name: MyTableName
type: source
schema:
- name: MyField1
type: INT
- name: MyField2
type: VARCHAR
connector:
type: filesystem
path: "/path/to/something.csv"
format:
type: csv
fields:
- name: MyField1
type: INT
- name: MyField2
type: VARCHAR
line-delimiter: "\n"
comment-prefix: "#"
# Execution properties allow for changing the behavior of a table program.
execution:
type: streaming
time-characteristic: event-time
parallelism: 1
max-parallelism: 16
min-idle-state-retention: 0
max-idle-state-retention: 0
result-mode: table
# Deployment properties allow for describing the cluster to which table programs are submitted to.
deployment:
response-timeout: 5000This configuration:
- defines an environment with a table source
MyTableNamethat reads from a CSV file, - specifies a parallelism of 1 for queries executed in this environment,
- specifies an even-time characteristic, and
- runs queries in the
tableresult mode.
Depending on the use case, a configuration can be split into multiple files. Therefore, environment files can be created for general purposes (defaults environment file using --defaults) as well as on a per-session basis (session environment file using --environment). Every CLI session is initialized with the default properties followed by the session properties. For example, the defaults environment file could specify all table sources that should be available for querying in every session whereas the session environment file only declares a specific state retention time and parallelism. Both default and session environment files can be passed when starting the CLI application. If no default environment file has been specified, the SQL Client searches for ./conf/sql-client-defaults.yaml in Flink’s configuration directory.
Attention Properties that have been set within a CLI session (e.g. using the SET command) have highest precedence:
CLI commands > session environment file > defaults environment fileDependencies
The SQL Client does not require to setup a Java project using Maven or SBT. Instead, you can pass the dependencies as regular JAR files that get submitted to the cluster. You can either specify each JAR file separately (using --jar) or define entire library directories (using --library). For connectors to external systems (such as Apache Kafka) and corresponding data formats (such as JSON), Flink provides ready-to-use JAR bundles. These JAR files are suffixed with sql-jar and can be downloaded for each release from the Maven central repository.
Connectors
| Name | Version | Download |
|---|---|---|
| Filesystem | Built-in | |
| Apache Kafka | 0.11 | Download |
Formats
| Name | Download |
|---|---|
| CSV | Built-in |
| JSON | Download |
Table Sources
Sources are defined using a set of YAML properties. Similar to a SQL CREATE TABLE statement you define the name of the table, the final schema of the table, connector, and a data format if necessary. Additionally, you have to specify its type (source, sink, or both).
name: MyTable # required: string representing the table name
type: source # required: currently only 'source' is supported
schema: ... # required: final table schema
connector: ... # required: connector configuration
format: ... # optional: format that depends on the connectorAttention Not every combination of connector and format is supported. Internally, your YAML file is translated into a set of string-based properties by which the SQL Client tries to resolve a matching table source. If a table source can be resolved also depends on the JAR files available in the classpath.
The following example shows an environment file that defines a table source reading JSON data from Apache Kafka. All properties are explained in the following subsections.
tables:
- name: TaxiRides
type: source
schema:
- name: rideId
type: LONG
- name: lon
type: FLOAT
- name: lat
type: FLOAT
- name: rowTime
type: TIMESTAMP
rowtime:
timestamps:
type: "from-field"
from: "rideTime"
watermarks:
type: "periodic-bounded"
delay: "60000"
- name: procTime
type: TIMESTAMP
proctime: true
connector:
property-version: 1
type: kafka
version: 0.11
topic: TaxiRides
startup-mode: earliest-offset
properties:
- key: zookeeper.connect
value: localhost:2181
- key: bootstrap.servers
value: localhost:9092
- key: group.id
value: testGroup
format:
property-version: 1
type: json
schema: "ROW(rideId LONG, lon FLOAT, lat FLOAT, rideTime TIMESTAMP)"The resulting schema of the TaxiRide table contains most of the fields of the JSON schema. Furthermore, it adds a rowtime attribute rowTime and processing-time attribute procTime. Both connector and format allow to define a property version (which is currently version 1) for future backwards compatibility.
Schema Properties
The schema allows for describing the final appearance of a table. It specifies the final name, final type, and the origin of a field. The origin of a field might be important if the name of the field should differ from the input format. For instance, a field name&field should reference nameField from an Avro format.
schema:
- name: MyField1
type: ...
- name: MyField2
type: ...
- name: MyField3
type: ...For each field, the following properties can be used:
name: ... # required: final name of the field
type: ... # required: final type of the field represented as a type string
proctime: ... # optional: boolean flag whether this field should be a processing-time attribute
rowtime: ... # optional: wether this field should be a event-time attribute
from: ... # optional: original field in the input that is referenced/aliased by this fieldType Strings
The following type strings are supported for being defined in an environment file:
VARCHAR
BOOLEAN
TINYINT
SMALLINT
INT
BIGINT
FLOAT
DOUBLE
DECIMAL
DATE
TIME
TIMESTAMP
ROW(fieldtype, ...) # unnamed row; e.g. ROW(VARCHAR, INT) that is mapped to Flink's RowTypeInfo
# with indexed fields names f0, f1, ...
ROW(fieldname fieldtype, ...) # named row; e.g., ROW(myField VARCHAR, myOtherField INT) that
# is mapped to Flink's RowTypeInfo
POJO(class) # e.g., POJO(org.mycompany.MyPojoClass) that is mapped to Flink's PojoTypeInfo
ANY(class) # e.g., ANY(org.mycompany.MyClass) that is mapped to Flink's GenericTypeInfo
ANY(class, serialized) # used for type information that is not supported by Flink's Table & SQL APIRowtime Properties
In order to control the event-time behavior for table sources, the SQL Client provides predefined timestamp extractors and watermark strategies. For more information about time handling in Flink and especially event-time, we recommend the general event-time section.
The following timestamp extractors are supported:
# Converts an existing BIGINT or TIMESTAMP field in the input into the rowtime attribute.
rowtime:
timestamps:
type: from-field
from: ... # required: original field name in the input
# Converts the assigned timestamps from a DataStream API record into the rowtime attribute
# and thus preserves the assigned timestamps from the source.
rowtime:
timestamps:
type: from-sourceThe following watermark strategies are supported:
# Sets a watermark strategy for ascending rowtime attributes. Emits a watermark of the maximum
# observed timestamp so far minus 1. Rows that have a timestamp equal to the max timestamp
# are not late.
rowtime:
watermarks:
type: periodic-ascending
# Sets a built-in watermark strategy for rowtime attributes which are out-of-order by a bounded time interval.
# Emits watermarks which are the maximum observed timestamp minus the specified delay.
rowtime:
watermarks:
type: periodic-bounded
delay: ... # required: delay in milliseconds
# Sets a built-in watermark strategy which indicates the watermarks should be preserved from the
# underlying DataStream API and thus preserves the assigned watermarks from the source.
rowtime:
watermarks:
type: from-sourceConnector Properties
Flink provides a set of connectors that can be defined in the environment file.
Attention Currently, connectors can only be used as table sources not sinks.
Filesystem Connector
The filesystem connector allows for reading from a local or distributed filesystem. A filesystem can be defined as:
connector:
type: filesystem
path: "file:///path/to/whatever" # requiredCurrently, only files with CSV format can be read from a filesystem. The filesystem connector is included in Flink and does not require an additional JAR file.
Kafka Connector
The Kafka connector allows for reading from a Apache Kafka topic. It can be defined as follows:
connector:
type: kafka
version: 0.11 # required: valid connector versions are "0.8", "0.9", "0.10", and "0.11"
topic: ... # required: topic name from which the table is read
startup-mode: ... # optional: valid modes are "earliest-offset", "latest-offset",
# "group-offsets", or "specific-offsets"
specific-offsets: # optional: used in case of startup mode with specific offsets
- partition: 0
offset: 42
- partition: 1
offset: 300
properties: # optional: connector specific properties
- key: zookeeper.connect
value: localhost:2181
- key: bootstrap.servers
value: localhost:9092
- key: group.id
value: testGroupMake sure to download the Kafka SQL JAR file and pass it to the SQL Client.
Format Properties
Flink provides a set of formats that can be defined in the environment file.
CSV Format
The CSV format allows to read comma-separated rows. Currently, this is only supported for the filesystem connector.
format:
type: csv
fields: # required: format fields
- name: field1
type: VARCHAR
- name: field2
type: TIMESTAMP
field-delimiter: "," # optional: string delimiter "," by default
line-delimiter: "\n" # optional: string delimiter "\n" by default
quote-character: '"' # optional: single character for string values, empty by default
comment-prefix: '#' # optional: string to indicate comments, empty by default
ignore-first-line: false # optional: boolean flag to ignore the first line, by default it is not skipped
ignore-parse-errors: true # optional: skip records with parse error instead to fail by defaultThe CSV format is included in Flink and does not require an additional JAR file.
JSON Format
The JSON format allows to read JSON data that corresponds to a given format schema. The format schema can be defined either as a Flink type string, as a JSON schema, or derived from the desired table schema. A type string enables a more SQL-like definition and mapping to the corresponding SQL data types. The JSON schema allows for more complex and nested structures.
If the format schema is equal to the table schema, the schema can also be automatically derived. This allows for defining schema information only once. The names, types, and field order of the format are determined by the table’s schema. Time attributes are ignored. A from definition in the table schema is interpreted as a field renaming in the format.
format:
type: json
fail-on-missing-field: true # optional: flag whether to fail if a field is missing or not
# required: define the schema either by using a type string which parses numbers to corresponding types
schema: "ROW(lon FLOAT, rideTime TIMESTAMP)"
# or by using a JSON schema which parses to DECIMAL and TIMESTAMP
json-schema: >
{
type: 'object',
properties: {
lon: {
type: 'number'
},
rideTime: {
type: 'string',
format: 'date-time'
}
}
}
# or use the tables schema
derive-schema: trueCurrently, Flink supports only a subset of the JSON schema specification draft-07. Union types (as well as allOf, anyOf, not) are not supported yet. oneOf and arrays of types are only supported for specifying nullability.
Simple references that link to a common definition in the document are supported as shown in the more complex example below:
{
"definitions": {
"address": {
"type": "object",
"properties": {
"street_address": {
"type": "string"
},
"city": {
"type": "string"
},
"state": {
"type": "string"
}
},
"required": [
"street_address",
"city",
"state"
]
}
},
"type": "object",
"properties": {
"billing_address": {
"$ref": "#/definitions/address"
},
"shipping_address": {
"$ref": "#/definitions/address"
},
"optional_address": {
"oneOf": [
{
"type": "null"
},
{
"$ref": "#/definitions/address"
}
]
}
}
}Make sure to download the JSON SQL JAR file and pass it to the SQL Client.
Limitations & Future
The current SQL Client implementation is in a very early development stage and might change in the future as part of the bigger Flink Improvement Proposal 24 (FLIP-24). Feel free to join the discussion and open issue about bugs and features that you find useful.