Data Pipelines & ETL
One very common use case for Apache Flink is to implement ETL (extract, transform, load) pipelines that take data from one or more sources, perform some transformations and/or enrichments, and then store the results somewhere. In this section we are going to look at how to use Flink’s DataStream API to implement this kind of application.
Note that Flink’s Table and SQL APIs are well suited for many ETL use cases. But regardless of whether you ultimately use the DataStream API directly, or not, having a solid understanding the basics presented here will prove valuable.
- Stateless Transformations
- Keyed Streams
- Stateful Transformations
- Connected Streams
- Hands-on
- Further Reading
Stateless Transformations
This section covers map() and flatmap(), the basic operations used to implement
stateless transformations. The examples in this section assume you are familiar with the
Taxi Ride data used in the hands-on exercises in the
flink-training repo.
map()
In the first exercise you filtered a stream of taxi ride events. In that same code base there’s a
GeoUtils class that provides a static method GeoUtils.mapToGridCell(float lon, float lat) which
maps a location (longitude, latitude) to a grid cell that refers to an area that is approximately
100x100 meters in size.
Now let’s enrich our stream of taxi ride objects by adding startCell and endCell fields to each
event. You can create an EnrichedRide object that extends TaxiRide, adding these fields:
public static class EnrichedRide extends TaxiRide {
public int startCell;
public int endCell;
public EnrichedRide() {}
public EnrichedRide(TaxiRide ride) {
this.rideId = ride.rideId;
this.isStart = ride.isStart;
...
this.startCell = GeoUtils.mapToGridCell(ride.startLon, ride.startLat);
this.endCell = GeoUtils.mapToGridCell(ride.endLon, ride.endLat);
}
public String toString() {
return super.toString() + "," +
Integer.toString(this.startCell) + "," +
Integer.toString(this.endCell);
}
}You can then create an application that transforms the stream
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));
DataStream<EnrichedRide> enrichedNYCRides = rides
.filter(new RideCleansingSolution.NYCFilter())
.map(new Enrichment());
enrichedNYCRides.print();with this MapFunction:
public static class Enrichment implements MapFunction<TaxiRide, EnrichedRide> {
@Override
public EnrichedRide map(TaxiRide taxiRide) throws Exception {
return new EnrichedRide(taxiRide);
}
}flatmap()
A MapFunction is suitable only when performing a one-to-one transformation: for each and every
stream element coming in, map() will emit one transformed element. Otherwise, you will want to use
flatmap()
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));
DataStream<EnrichedRide> enrichedNYCRides = rides
.flatMap(new NYCEnrichment());
enrichedNYCRides.print();together with a FlatMapFunction:
public static class NYCEnrichment implements FlatMapFunction<TaxiRide, EnrichedRide> {
@Override
public void flatMap(TaxiRide taxiRide, Collector<EnrichedRide> out) throws Exception {
FilterFunction<TaxiRide> valid = new RideCleansing.NYCFilter();
if (valid.filter(taxiRide)) {
out.collect(new EnrichedRide(taxiRide));
}
}
}With the Collector provided in this interface, the flatmap() method can emit as many stream
elements as you like, including none at all.
Keyed Streams
keyBy()
It is often very useful to be able to partition a stream around one of its attributes, so that all
events with the same value of that attribute are grouped together. For example, suppose you wanted
to find the longest taxi rides starting in each of the grid cells. Thinking in terms of a SQL query,
this would mean doing some sort of GROUP BY with the startCell, while in Flink this is done with
keyBy(KeySelector)
rides
.flatMap(new NYCEnrichment())
.keyBy(enrichedRide -> enrichedRide.startCell)Every keyBy causes a network shuffle that repartitions the stream. In general this is pretty
expensive, since it involves network communication along with serialization and deserialization.
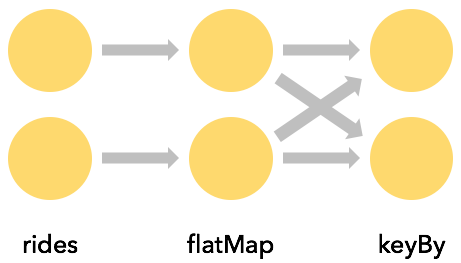
Keys are computed
KeySelectors aren’t limited to extracting a key from your events. They can, instead,
compute the key in whatever way you want, so long as the resulting key is deterministic,
and has valid implementations of hashCode() and equals(). This restriction rules out
KeySelectors that generate random numbers, or that return Arrays or Enums, but you
can have composite keys using Tuples or POJOs, for example, so long as their elements
follow these same rules.
The keys must be produced in a deterministic way, because they are recomputed whenever they are needed, rather than being attached to the stream records.
For example, rather than creating a new EnrichedRide class with a startCell field that we then use
as a key via
keyBy(enrichedRide -> enrichedRide.startCell)we could do this, instead:
keyBy(ride -> GeoUtils.mapToGridCell(ride.startLon, ride.startLat))Aggregations on Keyed Streams
This bit of code creates a new stream of tuples containing the startCell and duration (in minutes)
for each end-of-ride event:
import org.joda.time.Interval;
DataStream<Tuple2<Integer, Minutes>> minutesByStartCell = enrichedNYCRides
.flatMap(new FlatMapFunction<EnrichedRide, Tuple2<Integer, Minutes>>() {
@Override
public void flatMap(EnrichedRide ride,
Collector<Tuple2<Integer, Minutes>> out) throws Exception {
if (!ride.isStart) {
Interval rideInterval = new Interval(ride.startTime, ride.endTime);
Minutes duration = rideInterval.toDuration().toStandardMinutes();
out.collect(new Tuple2<>(ride.startCell, duration));
}
}
});Now it is possible to produce a stream that contains only those rides that are the longest rides
ever seen (to that point) for each startCell.
There are a variety of ways that the field to use as the key can be expressed. Earlier you saw an
example with an EnrichedRide POJO, where the field to use as the key was specified with its name.
This case involves Tuple2 objects, and the index within the tuple (starting from 0) is used to
specify the key.
minutesByStartCell
.keyBy(value -> value.f0) // .keyBy(value -> value.startCell)
.maxBy(1) // duration
.print();The output stream now contains a record for each key every time the duration reaches a new maximum – as shown here with cell 50797:
...
4> (64549,5M)
4> (46298,18M)
1> (51549,14M)
1> (53043,13M)
1> (56031,22M)
1> (50797,6M)
...
1> (50797,8M)
...
1> (50797,11M)
...
1> (50797,12M)
(Implicit) State
This is the first example in this training that involves stateful streaming. Though the state is being handled transparently, Flink has to keep track of the maximum duration for each distinct key.
Whenever state gets involved in your application, you should think about how large the state might become. Whenever the key space is unbounded, then so is the amount of state Flink will need.
When working with streams, it generally makes more sense to think in terms of aggregations over finite windows, rather than over the entire stream.
reduce() and other aggregators
maxBy(), used above, is just one example of a number of aggregator functions available on Flink’s
KeyedStreams. There is also a more general purpose reduce() function that you can use to
implement your own custom aggregations.
Stateful Transformations
Why is Flink Involved in Managing State?
Your applications are certainly capable of using state without getting Flink involved in managing it – but Flink offers some compelling features for the state it manages:
- local: Flink state is kept local to the machine that processes it, and can be accessed at memory speed
- durable: Flink state is fault-tolerant, i.e., it is automatically checkpointed at regular intervals, and is restored upon failure
- vertically scalable: Flink state can be kept in embedded RocksDB instances that scale by adding more local disk
- horizontally scalable: Flink state is redistributed as your cluster grows and shrinks
- queryable: Flink state can be queried externally via the Queryable State API.
In this section you will learn how to work with Flink’s APIs that manage keyed state.
Rich Functions
At this point you have already seen several of Flink’s function interfaces, including
FilterFunction, MapFunction, and FlatMapFunction. These are all examples of the Single
Abstract Method pattern.
For each of these interfaces, Flink also provides a so-called “rich” variant, e.g.,
RichFlatMapFunction, which has some additional methods, including:
open(Configuration c)close()getRuntimeContext()
open() is called once, during operator initialization. This is an opportunity to load some static
data, or to open a connection to an external service, for example.
getRuntimeContext() provides access to a whole suite of potentially interesting things, but most
notably it is how you can create and access state managed by Flink.
An Example with Keyed State
In this example, imagine you have a stream of events that you want to de-duplicate, so that you only
keep the first event with each key. Here’s an application that does that, using a
RichFlatMapFunction called Deduplicator:
private static class Event {
public final String key;
public final long timestamp;
...
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new EventSource())
.keyBy(e -> e.key)
.flatMap(new Deduplicator())
.print();
env.execute();
}To accomplish this, Deduplicator will need to somehow remember, for each key, whether or not there
has already been an event for that key. It will do so using Flink’s keyed state interface.
When you are working with a keyed stream like this one, Flink will maintain a key/value store for each item of state being managed.
Flink supports several different types of keyed state, and this example uses the simplest one,
namely ValueState. This means that for each key, Flink will store a single object – in this
case, an object of type Boolean.
Our Deduplicator class has two methods: open() and flatMap(). The open method establishes the
use of managed state by defining a ValueStateDescriptor<Boolean>. The arguments to the constructor
specify a name for this item of keyed state (“keyHasBeenSeen”), and provide information that can be
used to serialize these objects (in this case, Types.BOOLEAN).
public static class Deduplicator extends RichFlatMapFunction<Event, Event> {
ValueState<Boolean> keyHasBeenSeen;
@Override
public void open(Configuration conf) {
ValueStateDescriptor<Boolean> desc = new ValueStateDescriptor<>("keyHasBeenSeen", Types.BOOLEAN);
keyHasBeenSeen = getRuntimeContext().getState(desc);
}
@Override
public void flatMap(Event event, Collector<Event> out) throws Exception {
if (keyHasBeenSeen.value() == null) {
out.collect(event);
keyHasBeenSeen.update(true);
}
}
}When the flatMap method calls keyHasBeenSeen.value(), Flink’s runtime looks up the value of this
piece of state for the key in context, and only if it is null does it go ahead and collect the
event to the output. It also updates keyHasBeenSeen to true in this case.
This mechanism for accessing and updating key-partitioned state may seem rather magical, since the
key is not explicitly visible in the implementation of our Deduplicator. When Flink’s runtime
calls the open method of our RichFlatMapFunction, there is no event, and thus no key in context
at that moment. But when it calls the flatMap method, the key for the event being processed is
available to the runtime, and is used behind the scenes to determine which entry in Flink’s state
backend is being operated on.
When deployed to a distributed cluster, there will be many instances of this Deduplicator, each of
which will responsible for a disjoint subset of the entire keyspace. Thus, when you see a single
item of ValueState, such as
ValueState<Boolean> keyHasBeenSeen;understand that this represents not just a single Boolean, but rather a distributed, sharded, key/value store.
Clearing State
There’s a potential problem with the example above: What will happen if the key space is unbounded?
Flink is storing somewhere an instance of Boolean for every distinct key that is used. If there’s
a bounded set of keys then this will be fine, but in applications where the set of keys is growing
in an unbounded way, it’s necessary to clear the state for keys that are no longer needed. This is
done by calling clear() on the state object, as in:
keyHasBeenSeen.clear()You might want to do this, for example, after a period of inactivity for a given key. You’ll see how
to use Timers to do this when you learn about ProcessFunctions in the section on event-driven
applications.
There’s also a State Time-to-Live (TTL) option that you can configure with the state descriptor that specifies when you want the state for stale keys to be automatically cleared.
Non-keyed State
It is also possible to work with managed state in non-keyed contexts. This is sometimes called operator state. The interfaces involved are somewhat different, and since it is unusual for user-defined functions to need non-keyed state, it is not covered here. This feature is most often used in the implementation of sources and sinks.
Connected Streams
Sometimes instead of applying a pre-defined transformation like this:

you want to be able to dynamically alter some aspects of the transformation – by streaming in thresholds, or rules, or other parameters. The pattern in Flink that supports this is something called connected streams, wherein a single operator has two input streams, like this:

Connected streams can also be used to implement streaming joins.
Example
In this example, a control stream is used to specify words which must be filtered out of the
streamOfWords. A RichCoFlatMapFunction called ControlFunction is applied to the connected
streams to get this done.
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> control = env.fromElements("DROP", "IGNORE").keyBy(x -> x);
DataStream<String> streamOfWords = env.fromElements("Apache", "DROP", "Flink", "IGNORE").keyBy(x -> x);
control
.connect(datastreamOfWords)
.flatMap(new ControlFunction())
.print();
env.execute();
}Note that the two streams being connected must be keyed in compatible ways.
The role of a keyBy is to partition a stream’s data, and when keyed streams are connected, they
must be partitioned in the same way. This ensures that all of the events from both streams with the
same key are sent to the same instance. This makes it possible, then, to join the two streams on
that key, for example.
In this case the streams are both of type DataStream<String>, and both streams are keyed by the
string. As you will see below, this RichCoFlatMapFunction is storing a Boolean value in keyed
state, and this Boolean is shared by the two streams.
public static class ControlFunction extends RichCoFlatMapFunction<String, String, String> {
private ValueState<Boolean> blocked;
@Override
public void open(Configuration config) {
blocked = getRuntimeContext().getState(new ValueStateDescriptor<>("blocked", Boolean.class));
}
@Override
public void flatMap1(String control_value, Collector<String> out) throws Exception {
blocked.update(Boolean.TRUE);
}
@Override
public void flatMap2(String data_value, Collector<String> out) throws Exception {
if (blocked.value() == null) {
out.collect(data_value);
}
}
}A RichCoFlatMapFunction is a kind of FlatMapFunction that can be applied to a pair of connected
streams, and it has access to the rich function interface. This means that it can be made stateful.
The blocked Boolean is being used to remember the keys (words, in this case) that have been
mentioned on the control stream, and those words are being filtered out of the streamOfWords
stream. This is keyed state, and it is shared between the two streams, which is why the two
streams have to share the same keyspace.
flatMap1 and flatMap2 are called by the Flink runtime with elements from each of the two
connected streams – in our case, elements from the control stream are passed into flatMap1, and
elements from streamOfWords are passed into flatMap2. This was determined by the order in which
the two streams are connected with control.connect(datastreamOfWords).
It is important to recognize that you have no control over the order in which the flatMap1 and
flatMap2 callbacks are called. These two input streams are racing against each other, and the
Flink runtime will do what it wants to regarding consuming events from one stream or the other. In
cases where timing and/or ordering matter, you may find it necessary to buffer events in managed
Flink state until your application is ready to process them. (Note: if you are truly desperate, it
is possible to exert some limited control over the order in which a two-input operator consumes its
inputs by using a custom Operator that implements the
InputSelectable
interface.)
Hands-on
The hands-on exercise that goes with this section is the Rides and Fares Exercise.