![]() v1.7
v1.7
SQL Client Beta
Flink’s Table & SQL API makes it possible to work with queries written in the SQL language, but these queries need to be embedded within a table program that is written in either Java or Scala. Moreover, these programs need to be packaged with a build tool before being submitted to a cluster. This more or less limits the usage of Flink to Java/Scala programmers.
The SQL Client aims to provide an easy way of writing, debugging, and submitting table programs to a Flink cluster without a single line of Java or Scala code. The SQL Client CLI allows for retrieving and visualizing real-time results from the running distributed application on the command line.
Attention The SQL Client is in an early development phase. Even though the application is not production-ready yet, it can be a quite useful tool for prototyping and playing around with Flink SQL. In the future, the community plans to extend its functionality by providing a REST-based SQL Client Gateway.
Getting Started
This section describes how to setup and run your first Flink SQL program from the command-line.
The SQL Client is bundled in the regular Flink distribution and thus runnable out-of-the-box. It requires only a running Flink cluster where table programs can be executed. For more information about setting up a Flink cluster see the Cluster & Deployment part. If you simply want to try out the SQL Client, you can also start a local cluster with one worker using the following command:
./bin/start-cluster.shStarting the SQL Client CLI
The SQL Client scripts are also located in the binary directory of Flink. In the future, a user will have two possibilities of starting the SQL Client CLI either by starting an embedded standalone process or by connecting to a remote SQL Client Gateway. At the moment only the embedded mode is supported. You can start the CLI by calling:
./bin/sql-client.sh embeddedBy default, the SQL Client will read its configuration from the environment file located in ./conf/sql-client-defaults.yaml. See the configuration part for more information about the structure of environment files.
Running SQL Queries
Once the CLI has been started, you can use the HELP command to list all available SQL statements. For validating your setup and cluster connection, you can enter your first SQL query and press the Enter key to execute it:
SELECT 'Hello World';This query requires no table source and produces a single row result. The CLI will retrieve results from the cluster and visualize them. You can close the result view by pressing the Q key.
The CLI supports two modes for maintaining and visualizing results.
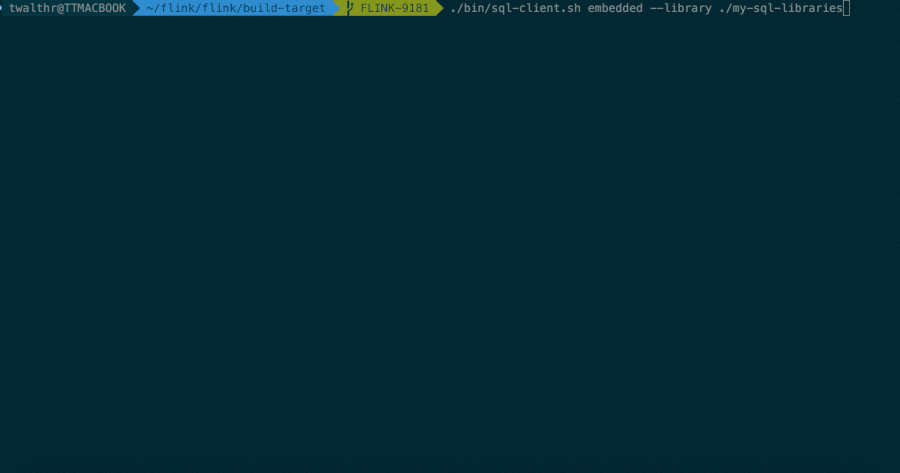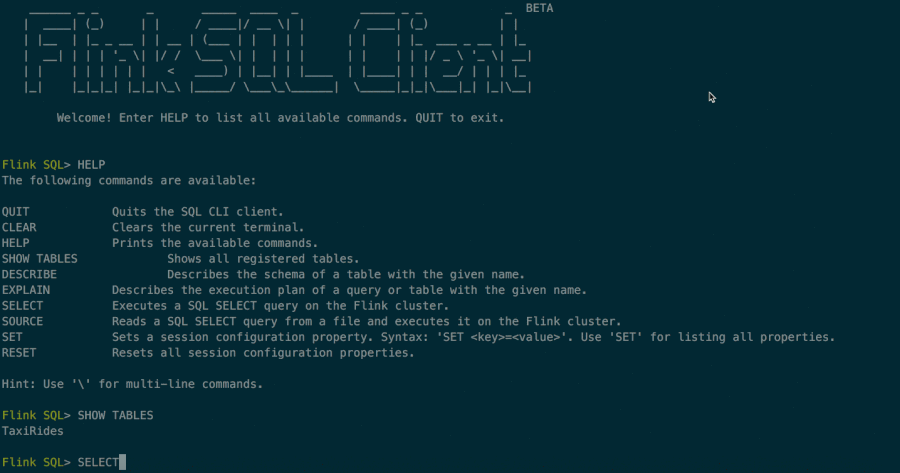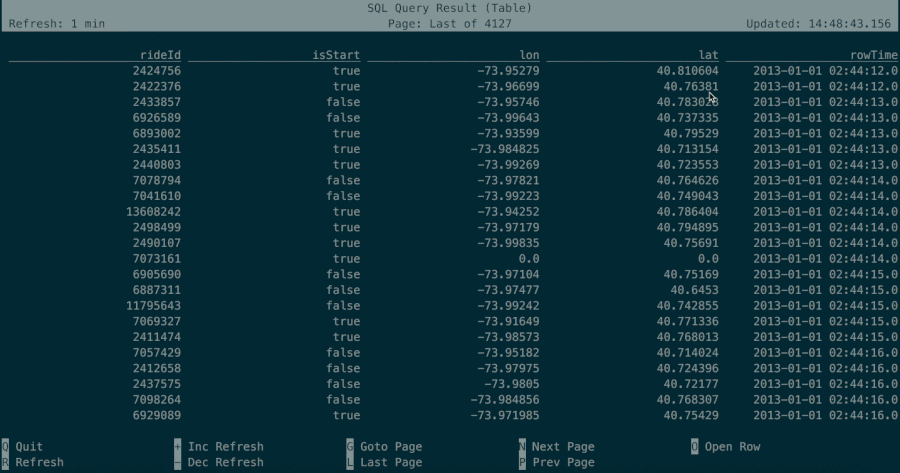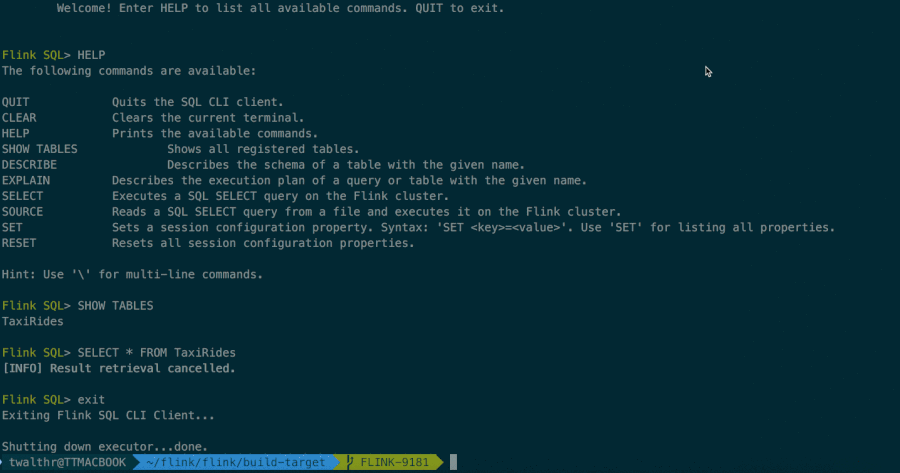
The table mode materializes results in memory and visualizes them in a regular, paginated table representation. It can be enabled by executing the following command in the CLI:
SET execution.result-mode=table;The changelog mode does not materialize results and visualizes the result stream that is produced by a continuous query consisting of insertions (+) and retractions (-).
SET execution.result-mode=changelog;You can use the following query to see both result modes in action:
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;This query performs a bounded word count example.
In changelog mode, the visualized changelog should be similar to:
+ Bob, 1
+ Alice, 1
+ Greg, 1
- Bob, 1
+ Bob, 2In table mode, the visualized result table is continuously updated until the table program ends with:
Bob, 2
Alice, 1
Greg, 1Both result modes can be useful during the prototyping of SQL queries. In both modes, results are stored in the Java heap memory of the SQL Client. In order to keep the CLI interface responsive, the changelog mode only shows the latest 1000 changes. The table mode allows for navigating through bigger results that are only limited by the available main memory and the configured maximum number of rows (max-table-result-rows).
Attention Queries that are executed in a batch environment, can only be retrieved using the table result mode.
After a query is defined, it can be submitted to the cluster as a long-running, detached Flink job. For this, a target system that stores the results needs to be specified using the INSERT INTO statement. The configuration section explains how to declare table sources for reading data, how to declare table sinks for writing data, and how to configure other table program properties.
Configuration
The SQL Client can be started with the following optional CLI commands. They are discussed in detail in the subsequent paragraphs.
./bin/sql-client.sh embedded --help
Mode "embedded" submits Flink jobs from the local machine.
Syntax: embedded [OPTIONS]
"embedded" mode options:
-d,--defaults <environment file> The environment properties with which
every new session is initialized.
Properties might be overwritten by
session properties.
-e,--environment <environment file> The environment properties to be
imported into the session. It might
overwrite default environment
properties.
-h,--help Show the help message with
descriptions of all options.
-j,--jar <JAR file> A JAR file to be imported into the
session. The file might contain
user-defined classes needed for the
execution of statements such as
functions, table sources, or sinks.
Can be used multiple times.
-l,--library <JAR directory> A JAR file directory with which every
new session is initialized. The files
might contain user-defined classes
needed for the execution of
statements such as functions, table
sources, or sinks. Can be used
multiple times.
-s,--session <session identifier> The identifier for a session.
'default' is the default identifier.Environment Files
A SQL query needs a configuration environment in which it is executed. The so-called environment files define available table sources and sinks, external catalogs, user-defined functions, and other properties required for execution and deployment.
Every environment file is a regular YAML file. An example of such a file is presented below.
# Define tables here such as sources, sinks, views, or temporal tables.
tables:
- name: MyTableSource
type: source-table
update-mode: append
connector:
type: filesystem
path: "/path/to/something.csv"
format:
type: csv
fields:
- name: MyField1
type: INT
- name: MyField2
type: VARCHAR
line-delimiter: "\n"
comment-prefix: "#"
schema:
- name: MyField1
type: INT
- name: MyField2
type: VARCHAR
- name: MyCustomView
type: view
query: "SELECT MyField2 FROM MyTableSource"
# Define user-defined functions here.
functions:
- name: myUDF
from: class
class: foo.bar.AggregateUDF
constructor:
- 7.6
- false
# Execution properties allow for changing the behavior of a table program.
execution:
type: streaming # required: execution mode either 'batch' or 'streaming'
result-mode: table # required: either 'table' or 'changelog'
max-table-result-rows: 1000000 # optional: maximum number of maintained rows in
# 'table' mode (1000000 by default, smaller 1 means unlimited)
time-characteristic: event-time # optional: 'processing-time' or 'event-time' (default)
parallelism: 1 # optional: Flink's parallelism (1 by default)
periodic-watermarks-interval: 200 # optional: interval for periodic watermarks (200 ms by default)
max-parallelism: 16 # optional: Flink's maximum parallelism (128 by default)
min-idle-state-retention: 0 # optional: table program's minimum idle state time
max-idle-state-retention: 0 # optional: table program's maximum idle state time
restart-strategy: # optional: restart strategy
type: fallback # "fallback" to global restart strategy by default
# Deployment properties allow for describing the cluster to which table programs are submitted to.
deployment:
response-timeout: 5000This configuration:
- defines an environment with a table source
MyTableSourcethat reads from a CSV file, - defines a view
MyCustomViewthat declares a virtual table using a SQL query, - defines a user-defined function
myUDFthat can be instantiated using the class name and two constructor parameters, - specifies a parallelism of 1 for queries executed in this streaming environment,
- specifies an event-time characteristic, and
- runs queries in the
tableresult mode.
Depending on the use case, a configuration can be split into multiple files. Therefore, environment files can be created for general purposes (defaults environment file using --defaults) as well as on a per-session basis (session environment file using --environment). Every CLI session is initialized with the default properties followed by the session properties. For example, the defaults environment file could specify all table sources that should be available for querying in every session whereas the session environment file only declares a specific state retention time and parallelism. Both default and session environment files can be passed when starting the CLI application. If no default environment file has been specified, the SQL Client searches for ./conf/sql-client-defaults.yaml in Flink’s configuration directory.
Attention Properties that have been set within a CLI session (e.g. using the SET command) have highest precedence:
CLI commands > session environment file > defaults environment fileRestart Strategies
Restart strategies control how Flink jobs are restarted in case of a failure. Similar to global restart strategies for a Flink cluster, a more fine-grained restart configuration can be declared in an environment file.
The following strategies are supported:
execution:
# falls back to the global strategy defined in flink-conf.yaml
restart-strategy:
type: fallback
# job fails directly and no restart is attempted
restart-strategy:
type: none
# attempts a given number of times to restart the job
restart-strategy:
type: fixed-delay
attempts: 3 # retries before job is declared as failed (default: Integer.MAX_VALUE)
delay: 10000 # delay in ms between retries (default: 10 s)
# attempts as long as the maximum number of failures per time interval is not exceeded
restart-strategy:
type: failure-rate
max-failures-per-interval: 1 # retries in interval until failing (default: 1)
failure-rate-interval: 60000 # measuring interval in ms for failure rate
delay: 10000 # delay in ms between retries (default: 10 s)Dependencies
The SQL Client does not require to setup a Java project using Maven or SBT. Instead, you can pass the dependencies as regular JAR files that get submitted to the cluster. You can either specify each JAR file separately (using --jar) or define entire library directories (using --library). For connectors to external systems (such as Apache Kafka) and corresponding data formats (such as JSON), Flink provides ready-to-use JAR bundles. These JAR files are suffixed with sql-jar and can be downloaded for each release from the Maven central repository.
The full list of offered SQL JARs and documentation about how to use them can be found on the connection to external systems page.
The following example shows an environment file that defines a table source reading JSON data from Apache Kafka.
tables:
- name: TaxiRides
type: source-table
update-mode: append
connector:
property-version: 1
type: kafka
version: "0.11"
topic: TaxiRides
startup-mode: earliest-offset
properties:
- key: zookeeper.connect
value: localhost:2181
- key: bootstrap.servers
value: localhost:9092
- key: group.id
value: testGroup
format:
property-version: 1
type: json
schema: "ROW<rideId LONG, lon FLOAT, lat FLOAT, rideTime TIMESTAMP>"
schema:
- name: rideId
type: LONG
- name: lon
type: FLOAT
- name: lat
type: FLOAT
- name: rowTime
type: TIMESTAMP
rowtime:
timestamps:
type: "from-field"
from: "rideTime"
watermarks:
type: "periodic-bounded"
delay: "60000"
- name: procTime
type: TIMESTAMP
proctime: trueThe resulting schema of the TaxiRide table contains most of the fields of the JSON schema. Furthermore, it adds a rowtime attribute rowTime and processing-time attribute procTime.
Both connector and format allow to define a property version (which is currently version 1) for future backwards compatibility.
User-defined Functions
The SQL Client allows users to create custom, user-defined functions to be used in SQL queries. Currently, these functions are restricted to be defined programmatically in Java/Scala classes.
In order to provide a user-defined function, you need to first implement and compile a function class that extends ScalarFunction, AggregateFunction or TableFunction (see User-defined Functions). One or more functions can then be packaged into a dependency JAR for the SQL Client.
All functions must be declared in an environment file before being called. For each item in the list of functions, one must specify
- a
nameunder which the function is registered, - the source of the function using
from(restricted to beclassfor now), - the
classwhich indicates the fully qualified class name of the function and an optional list ofconstructorparameters for instantiation.
functions:
- name: ... # required: name of the function
from: class # required: source of the function (can only be "class" for now)
class: ... # required: fully qualified class name of the function
constructor: # optimal: constructor parameters of the function class
- ... # optimal: a literal parameter with implicit type
- class: ... # optimal: full class name of the parameter
constructor: # optimal: constructor parameters of the parameter's class
- type: ... # optimal: type of the literal parameter
value: ... # optimal: value of the literal parameterMake sure that the order and types of the specified parameters strictly match one of the constructors of your function class.
Constructor Parameters
Depending on the user-defined function, it might be necessary to parameterize the implementation before using it in SQL statements.
As shown in the example before, when declaring a user-defined function, a class can be configured using constructor parameters in one of the following three ways:
A literal value with implicit type: The SQL Client will automatically derive the type according to the literal value itself. Currently, only values of BOOLEAN, INT, DOUBLE and VARCHAR are supported here.
If the automatic derivation does not work as expected (e.g., you need a VARCHAR false), use explicit types instead.
- true # -> BOOLEAN (case sensitive)
- 42 # -> INT
- 1234.222 # -> DOUBLE
- foo # -> VARCHARA literal value with explicit type: Explicitly declare the parameter with type and value properties for type-safety.
- type: DECIMAL
value: 11111111111111111The table below illustrates the supported Java parameter types and the corresponding SQL type strings.
| Java type | SQL type |
|---|---|
java.math.BigDecimal |
DECIMAL |
java.lang.Boolean |
BOOLEAN |
java.lang.Byte |
TINYINT |
java.lang.Double |
DOUBLE |
java.lang.Float |
REAL, FLOAT |
java.lang.Integer |
INTEGER, INT |
java.lang.Long |
BIGINT |
java.lang.Short |
SMALLINT |
java.lang.String |
VARCHAR |
More types (e.g., TIMESTAMP or ARRAY), primitive types, and null are not supported yet.
A (nested) class instance: Besides literal values, you can also create (nested) class instances for constructor parameters by specifying the class and constructor properties.
This process can be recursively performed until all the constructor parameters are represented with literal values.
- class: foo.bar.paramClass
constructor:
- StarryName
- class: java.lang.Integer
constructor:
- class: java.lang.String
constructor:
- type: VARCHAR
value: 3Detached SQL Queries
In order to define end-to-end SQL pipelines, SQL’s INSERT INTO statement can be used for submitting long-running, detached queries to a Flink cluster. These queries produce their results into an external system instead of the SQL Client. This allows for dealing with higher parallelism and larger amounts of data. The CLI itself does not have any control over a detached query after submission.
INSERT INTO MyTableSink SELECT * FROM MyTableSourceThe table sink MyTableSink has to be declared in the environment file. See the connection page for more information about supported external systems and their configuration. An example for an Apache Kafka table sink is shown below.
tables:
- name: MyTableSink
type: sink-table
update-mode: append
connector:
property-version: 1
type: kafka
version: "0.11"
topic: OutputTopic
properties:
- key: zookeeper.connect
value: localhost:2181
- key: bootstrap.servers
value: localhost:9092
- key: group.id
value: testGroup
format:
property-version: 1
type: json
derive-schema: true
schema:
- name: rideId
type: LONG
- name: lon
type: FLOAT
- name: lat
type: FLOAT
- name: rideTime
type: TIMESTAMPThe SQL Client makes sure that a statement is successfully submitted to the cluster. Once the query is submitted, the CLI will show information about the Flink job.
[INFO] Table update statement has been successfully submitted to the cluster:
Cluster ID: StandaloneClusterId
Job ID: 6f922fe5cba87406ff23ae4a7bb79044
Web interface: http://localhost:8081Attention The SQL Client does not track the status of the running Flink job after submission. The CLI process can be shutdown after the submission without affecting the detached query. Flink’s restart strategy takes care of the fault-tolerance. A query can be cancelled using Flink’s web interface, command-line, or REST API.
SQL Views
Views allow to define virtual tables from SQL queries. The view definition is parsed and validated immediately. However, the actual execution happens when the view is accessed during the submission of a general INSERT INTO or SELECT statement.
Views can either be defined in environment files or within the CLI session.
The following example shows how to define multiple views in a file. The views are registered in the order in which they are defined in the environment file. Reference chains such as view A depends on view B depends on view C are supported.
tables:
- name: MyTableSource
# ...
- name: MyRestrictedView
type: view
query: "SELECT MyField2 FROM MyTableSource"
- name: MyComplexView
type: view
query: >
SELECT MyField2 + 42, CAST(MyField1 AS VARCHAR)
FROM MyTableSource
WHERE MyField2 > 200Similar to table sources and sinks, views defined in a session environment file have highest precedence.
Views can also be created within a CLI session using the CREATE VIEW statement:
CREATE VIEW MyNewView AS SELECT MyField2 FROM MyTableSource;Views created within a CLI session can also be removed again using the DROP VIEW statement:
DROP VIEW MyNewView;Attention The definition of views in the CLI is limited to the mentioned syntax above. Defining a schema for views or escaping whitespaces in table names will be supported in future versions.
Temporal Tables
A temporal table allows for a (parameterized) view on a changing history table that returns the content of a table at a specific point in time. This is especially useful for joining a table with the content of another table at a particular timestamp. More information can be found in the temporal table joins page.
The following example shows how to define a temporal table SourceTemporalTable:
tables:
# Define the table source (or view) that contains updates to a temporal table
- name: HistorySource
type: source-table
update-mode: append
connector: # ...
format: # ...
schema:
- name: integerField
type: INT
- name: stringField
type: VARCHAR
- name: rowtimeField
type: TIMESTAMP
rowtime:
timestamps:
type: from-field
from: rowtimeField
watermarks:
type: from-source
# Define a temporal table over the changing history table with time attribute and primary key
- name: SourceTemporalTable
type: temporal-table
history-table: HistorySource
primary-key: integerField
time-attribute: rowtimeField # could also be a proctime fieldAs shown in the example, definitions of table sources, views, and temporal tables can be mixed with each other. They are registered in the order in which they are defined in the environment file. For example, a temporal table can reference a view which can depend on another view or table source.
Limitations & Future
The current SQL Client implementation is in a very early development stage and might change in the future as part of the bigger Flink Improvement Proposal 24 (FLIP-24). Feel free to join the discussion and open issue about bugs and features that you find useful.