![]() v1.4
v1.4
Iterative Graph Processing
Gelly exploits Flink’s efficient iteration operators to support large-scale iterative graph processing. Currently, we provide implementations of the vertex-centric, scatter-gather, and gather-sum-apply models. In the following sections, we describe these abstractions and show how you can use them in Gelly.
- Vertex-Centric Iterations
- Configuring a Vertex-Centric Iteration
- Scatter-Gather Iterations
- Configuring a Scatter-Gather Iteration
- Gather-Sum-Apply Iterations
- Configuring a Gather-Sum-Apply Iteration
- Iteration Abstractions Comparison
Vertex-Centric Iterations
The vertex-centric model, also known as “think like a vertex” or “Pregel”, expresses computation from the perspective of a vertex in the graph. The computation proceeds in synchronized iteration steps, called supersteps. In each superstep, each vertex executes one user-defined function. Vertices communicate with other vertices through messages. A vertex can send a message to any other vertex in the graph, as long as it knows its unique ID.
The computational model is shown in the figure below. The dotted boxes correspond to parallelization units. In each superstep, all active vertices execute the same user-defined computation in parallel. Supersteps are executed synchronously, so that messages sent during one superstep are guaranteed to be delivered in the beginning of the next superstep.
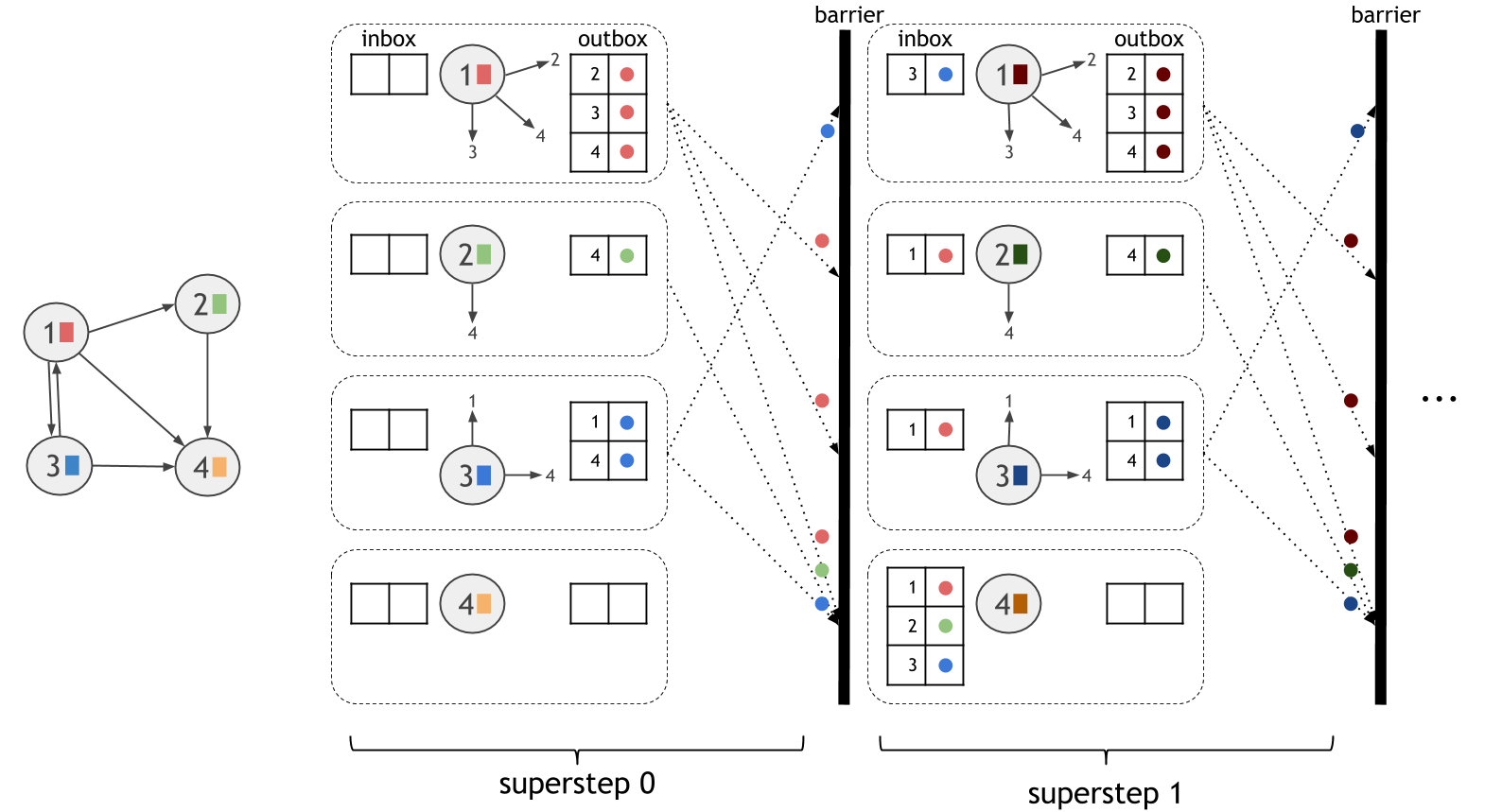
To use vertex-centric iterations in Gelly, the user only needs to define the vertex compute function, ComputeFunction.
This function and the maximum number of iterations to run are given as parameters to Gelly’s runVertexCentricIteration. This method will execute the vertex-centric iteration on the input Graph and return a new Graph, with updated vertex values. An optional message combiner, MessageCombiner, can be defined to reduce communication costs.
Let us consider computing Single-Source-Shortest-Paths with vertex-centric iterations. Initially, each vertex has a value of infinite distance, except from the source vertex, which has a value of zero. During the first superstep, the source propagates distances to its neighbors. During the following supersteps, each vertex checks its received messages and chooses the minimum distance among them. If this distance is smaller than its current value, it updates its state and produces messages for its neighbors. If a vertex does not change its value during a superstep, then it does not produce any messages for its neighbors for the next superstep. The algorithm converges when there are no value updates or the maximum number of supersteps has been reached. In this algorithm, a message combiner can be used to reduce the number of messages sent to a target vertex.
// read the input graph
Graph<Long, Double, Double> graph = ...
// define the maximum number of iterations
int maxIterations = 10;
// Execute the vertex-centric iteration
Graph<Long, Double, Double> result = graph.runVertexCentricIteration(
new SSSPComputeFunction(), new SSSPCombiner(), maxIterations);
// Extract the vertices as the result
DataSet<Vertex<Long, Double>> singleSourceShortestPaths = result.getVertices();
// - - - UDFs - - - //
public static final class SSSPComputeFunction extends ComputeFunction<Long, Double, Double, Double> {
public void compute(Vertex<Long, Double> vertex, MessageIterator<Double> messages) {
double minDistance = (vertex.getId().equals(srcId)) ? 0d : Double.POSITIVE_INFINITY;
for (Double msg : messages) {
minDistance = Math.min(minDistance, msg);
}
if (minDistance < vertex.getValue()) {
setNewVertexValue(minDistance);
for (Edge<Long, Double> e: getEdges()) {
sendMessageTo(e.getTarget(), minDistance + e.getValue());
}
}
}
// message combiner
public static final class SSSPCombiner extends MessageCombiner<Long, Double> {
public void combineMessages(MessageIterator<Double> messages) {
double minMessage = Double.POSITIVE_INFINITY;
for (Double msg: messages) {
minMessage = Math.min(minMessage, msg);
}
sendCombinedMessage(minMessage);
}
}// read the input graph
val graph: Graph[Long, Double, Double] = ...
// define the maximum number of iterations
val maxIterations = 10
// Execute the vertex-centric iteration
val result = graph.runVertexCentricIteration(new SSSPComputeFunction, new SSSPCombiner, maxIterations)
// Extract the vertices as the result
val singleSourceShortestPaths = result.getVertices
// - - - UDFs - - - //
final class SSSPComputeFunction extends ComputeFunction[Long, Double, Double, Double] {
override def compute(vertex: Vertex[Long, Double], messages: MessageIterator[Double]) = {
var minDistance = if (vertex.getId.equals(srcId)) 0 else Double.MaxValue
while (messages.hasNext) {
val msg = messages.next
if (msg < minDistance) {
minDistance = msg
}
}
if (vertex.getValue > minDistance) {
setNewVertexValue(minDistance)
for (edge: Edge[Long, Double] <- getEdges) {
sendMessageTo(edge.getTarget, vertex.getValue + edge.getValue)
}
}
}
// message combiner
final class SSSPCombiner extends MessageCombiner[Long, Double] {
override def combineMessages(messages: MessageIterator[Double]) {
var minDistance = Double.MaxValue
while (messages.hasNext) {
val msg = inMessages.next
if (msg < minDistance) {
minDistance = msg
}
}
sendCombinedMessage(minMessage)
}
}Configuring a Vertex-Centric Iteration
A vertex-centric iteration can be configured using a VertexCentricConfiguration object.
Currently, the following parameters can be specified:
-
Name: The name for the vertex-centric iteration. The name is displayed in logs and messages and can be specified using the
setName()method. -
Parallelism: The parallelism for the iteration. It can be set using the
setParallelism()method. -
Solution set in unmanaged memory: Defines whether the solution set is kept in managed memory (Flink’s internal way of keeping objects in serialized form) or as a simple object map. By default, the solution set runs in managed memory. This property can be set using the
setSolutionSetUnmanagedMemory()method. -
Aggregators: Iteration aggregators can be registered using the
registerAggregator()method. An iteration aggregator combines all aggregates globally once per superstep and makes them available in the next superstep. Registered aggregators can be accessed inside the user-definedComputeFunction. -
Broadcast Variables: DataSets can be added as Broadcast Variables to the
ComputeFunction, using theaddBroadcastSet()method.
Graph<Long, Double, Double> graph = ...
// configure the iteration
VertexCentricConfiguration parameters = new VertexCentricConfiguration();
// set the iteration name
parameters.setName("Gelly Iteration");
// set the parallelism
parameters.setParallelism(16);
// register an aggregator
parameters.registerAggregator("sumAggregator", new LongSumAggregator());
// run the vertex-centric iteration, also passing the configuration parameters
Graph<Long, Long, Double> result =
graph.runVertexCentricIteration(
new Compute(), null, maxIterations, parameters);
// user-defined function
public static final class Compute extends ComputeFunction {
LongSumAggregator aggregator = new LongSumAggregator();
public void preSuperstep() {
// retrieve the Aggregator
aggregator = getIterationAggregator("sumAggregator");
}
public void compute(Vertex<Long, Long> vertex, MessageIterator inMessages) {
//do some computation
Long partialValue = ...
// aggregate the partial value
aggregator.aggregate(partialValue);
// update the vertex value
setNewVertexValue(...);
}
}val graph: Graph[Long, Long, Double] = ...
val parameters = new VertexCentricConfiguration
// set the iteration name
parameters.setName("Gelly Iteration")
// set the parallelism
parameters.setParallelism(16)
// register an aggregator
parameters.registerAggregator("sumAggregator", new LongSumAggregator)
// run the vertex-centric iteration, also passing the configuration parameters
val result = graph.runVertexCentricIteration(new Compute, new Combiner, maxIterations, parameters)
// user-defined function
final class Compute extends ComputeFunction {
var aggregator = new LongSumAggregator
override def preSuperstep {
// retrieve the Aggregator
aggregator = getIterationAggregator("sumAggregator")
}
override def compute(vertex: Vertex[Long, Long], inMessages: MessageIterator[Long]) {
//do some computation
val partialValue = ...
// aggregate the partial value
aggregator.aggregate(partialValue)
// update the vertex value
setNewVertexValue(...)
}
}Scatter-Gather Iterations
The scatter-gather model, also known as “signal/collect” model, expresses computation from the perspective of a vertex in the graph. The computation proceeds in synchronized iteration steps, called supersteps. In each superstep, a vertex produces messages for other vertices and updates its value based on the messages it receives. To use scatter-gather iterations in Gelly, the user only needs to define how a vertex behaves in each superstep:
- Scatter: produces the messages that a vertex will send to other vertices.
- Gather: updates the vertex value using received messages.
Gelly provides methods for scatter-gather iterations. The user only needs to implement two functions, corresponding to the scatter and gather phases. The first function is a ScatterFunction, which allows a vertex to send out messages to other vertices. Messages are received during the same superstep as they are sent. The second function is GatherFunction, which defines how a vertex will update its value based on the received messages.
These functions and the maximum number of iterations to run are given as parameters to Gelly’s runScatterGatherIteration. This method will execute the scatter-gather iteration on the input Graph and return a new Graph, with updated vertex values.
A scatter-gather iteration can be extended with information such as the total number of vertices, the in degree and out degree. Additionally, the neighborhood type (in/out/all) over which to run the scatter-gather iteration can be specified. By default, the updates from the in-neighbors are used to modify the current vertex’s state and messages are sent to out-neighbors.
Let us consider computing Single-Source-Shortest-Paths with scatter-gather iterations on the following graph and let vertex 1 be the source. In each superstep, each vertex sends a candidate distance message to all its neighbors. The message value is the sum of the current value of the vertex and the edge weight connecting this vertex with its neighbor. Upon receiving candidate distance messages, each vertex calculates the minimum distance and, if a shorter path has been discovered, it updates its value. If a vertex does not change its value during a superstep, then it does not produce messages for its neighbors for the next superstep. The algorithm converges when there are no value updates.
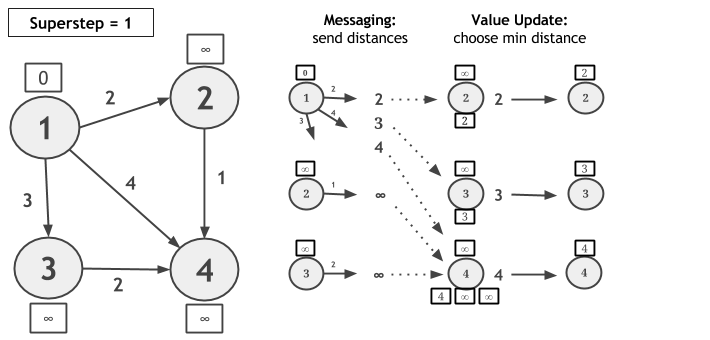
// read the input graph
Graph<Long, Double, Double> graph = ...
// define the maximum number of iterations
int maxIterations = 10;
// Execute the scatter-gather iteration
Graph<Long, Double, Double> result = graph.runScatterGatherIteration(
new MinDistanceMessenger(), new VertexDistanceUpdater(), maxIterations);
// Extract the vertices as the result
DataSet<Vertex<Long, Double>> singleSourceShortestPaths = result.getVertices();
// - - - UDFs - - - //
// scatter: messaging
public static final class MinDistanceMessenger extends ScatterFunction<Long, Double, Double, Double> {
public void sendMessages(Vertex<Long, Double> vertex) {
for (Edge<Long, Double> edge : getEdges()) {
sendMessageTo(edge.getTarget(), vertex.getValue() + edge.getValue());
}
}
}
// gather: vertex update
public static final class VertexDistanceUpdater extends GatherFunction<Long, Double, Double> {
public void updateVertex(Vertex<Long, Double> vertex, MessageIterator<Double> inMessages) {
Double minDistance = Double.MAX_VALUE;
for (double msg : inMessages) {
if (msg < minDistance) {
minDistance = msg;
}
}
if (vertex.getValue() > minDistance) {
setNewVertexValue(minDistance);
}
}
}// read the input graph
val graph: Graph[Long, Double, Double] = ...
// define the maximum number of iterations
val maxIterations = 10
// Execute the scatter-gather iteration
val result = graph.runScatterGatherIteration(new MinDistanceMessenger, new VertexDistanceUpdater, maxIterations)
// Extract the vertices as the result
val singleSourceShortestPaths = result.getVertices
// - - - UDFs - - - //
// messaging
final class MinDistanceMessenger extends ScatterFunction[Long, Double, Double, Double] {
override def sendMessages(vertex: Vertex[Long, Double]) = {
for (edge: Edge[Long, Double] <- getEdges) {
sendMessageTo(edge.getTarget, vertex.getValue + edge.getValue)
}
}
}
// vertex update
final class VertexDistanceUpdater extends GatherFunction[Long, Double, Double] {
override def updateVertex(vertex: Vertex[Long, Double], inMessages: MessageIterator[Double]) = {
var minDistance = Double.MaxValue
while (inMessages.hasNext) {
val msg = inMessages.next
if (msg < minDistance) {
minDistance = msg
}
}
if (vertex.getValue > minDistance) {
setNewVertexValue(minDistance)
}
}
}Configuring a Scatter-Gather Iteration
A scatter-gather iteration can be configured using a ScatterGatherConfiguration object.
Currently, the following parameters can be specified:
-
Name: The name for the scatter-gather iteration. The name is displayed in logs and messages and can be specified using the
setName()method. -
Parallelism: The parallelism for the iteration. It can be set using the
setParallelism()method. -
Solution set in unmanaged memory: Defines whether the solution set is kept in managed memory (Flink’s internal way of keeping objects in serialized form) or as a simple object map. By default, the solution set runs in managed memory. This property can be set using the
setSolutionSetUnmanagedMemory()method. -
Aggregators: Iteration aggregators can be registered using the
registerAggregator()method. An iteration aggregator combines all aggregates globally once per superstep and makes them available in the next superstep. Registered aggregators can be accessed inside the user-definedScatterFunctionandGatherFunction. -
Broadcast Variables: DataSets can be added as Broadcast Variables to the
ScatterFunctionandGatherFunction, using theaddBroadcastSetForUpdateFunction()andaddBroadcastSetForMessagingFunction()methods, respectively. -
Number of Vertices: Accessing the total number of vertices within the iteration. This property can be set using the
setOptNumVertices()method. The number of vertices can then be accessed in the vertex update function and in the messaging function using thegetNumberOfVertices()method. If the option is not set in the configuration, this method will return -1. -
Degrees: Accessing the in/out degree for a vertex within an iteration. This property can be set using the
setOptDegrees()method. The in/out degrees can then be accessed in the vertex update function and in the messaging function, per vertex using thegetInDegree()andgetOutDegree()methods. If the degrees option is not set in the configuration, these methods will return -1. -
Messaging Direction: By default, a vertex sends messages to its out-neighbors and updates its value based on messages received from its in-neighbors. This configuration option allows users to change the messaging direction to either
EdgeDirection.IN,EdgeDirection.OUT,EdgeDirection.ALL. The messaging direction also dictates the update direction which would beEdgeDirection.OUT,EdgeDirection.INandEdgeDirection.ALL, respectively. This property can be set using thesetDirection()method.
Graph<Long, Double, Double> graph = ...
// configure the iteration
ScatterGatherConfiguration parameters = new ScatterGatherConfiguration();
// set the iteration name
parameters.setName("Gelly Iteration");
// set the parallelism
parameters.setParallelism(16);
// register an aggregator
parameters.registerAggregator("sumAggregator", new LongSumAggregator());
// run the scatter-gather iteration, also passing the configuration parameters
Graph<Long, Double, Double> result =
graph.runScatterGatherIteration(
new Messenger(), new VertexUpdater(), maxIterations, parameters);
// user-defined functions
public static final class Messenger extends ScatterFunction {...}
public static final class VertexUpdater extends GatherFunction {
LongSumAggregator aggregator = new LongSumAggregator();
public void preSuperstep() {
// retrieve the Aggregator
aggregator = getIterationAggregator("sumAggregator");
}
public void updateVertex(Vertex<Long, Long> vertex, MessageIterator inMessages) {
//do some computation
Long partialValue = ...
// aggregate the partial value
aggregator.aggregate(partialValue);
// update the vertex value
setNewVertexValue(...);
}
}val graph: Graph[Long, Double, Double] = ...
val parameters = new ScatterGatherConfiguration
// set the iteration name
parameters.setName("Gelly Iteration")
// set the parallelism
parameters.setParallelism(16)
// register an aggregator
parameters.registerAggregator("sumAggregator", new LongSumAggregator)
// run the scatter-gather iteration, also passing the configuration parameters
val result = graph.runScatterGatherIteration(new Messenger, new VertexUpdater, maxIterations, parameters)
// user-defined functions
final class Messenger extends ScatterFunction {...}
final class VertexUpdater extends GatherFunction {
var aggregator = new LongSumAggregator
override def preSuperstep {
// retrieve the Aggregator
aggregator = getIterationAggregator("sumAggregator")
}
override def updateVertex(vertex: Vertex[Long, Long], inMessages: MessageIterator[Long]) {
//do some computation
val partialValue = ...
// aggregate the partial value
aggregator.aggregate(partialValue)
// update the vertex value
setNewVertexValue(...)
}
}The following example illustrates the usage of the degree as well as the number of vertices options.
Graph<Long, Double, Double> graph = ...
// configure the iteration
ScatterGatherConfiguration parameters = new ScatterGatherConfiguration();
// set the number of vertices option to true
parameters.setOptNumVertices(true);
// set the degree option to true
parameters.setOptDegrees(true);
// run the scatter-gather iteration, also passing the configuration parameters
Graph<Long, Double, Double> result =
graph.runScatterGatherIteration(
new Messenger(), new VertexUpdater(), maxIterations, parameters);
// user-defined functions
public static final class Messenger extends ScatterFunction {
...
// retrieve the vertex out-degree
outDegree = getOutDegree();
...
}
public static final class VertexUpdater extends GatherFunction {
...
// get the number of vertices
long numVertices = getNumberOfVertices();
...
}val graph: Graph[Long, Double, Double] = ...
// configure the iteration
val parameters = new ScatterGatherConfiguration
// set the number of vertices option to true
parameters.setOptNumVertices(true)
// set the degree option to true
parameters.setOptDegrees(true)
// run the scatter-gather iteration, also passing the configuration parameters
val result = graph.runScatterGatherIteration(new Messenger, new VertexUpdater, maxIterations, parameters)
// user-defined functions
final class Messenger extends ScatterFunction {
...
// retrieve the vertex out-degree
val outDegree = getOutDegree
...
}
final class VertexUpdater extends GatherFunction {
...
// get the number of vertices
val numVertices = getNumberOfVertices
...
}The following example illustrates the usage of the edge direction option. Vertices update their values to contain a list of all their in-neighbors.
Graph<Long, HashSet<Long>, Double> graph = ...
// configure the iteration
ScatterGatherConfiguration parameters = new ScatterGatherConfiguration();
// set the messaging direction
parameters.setDirection(EdgeDirection.IN);
// run the scatter-gather iteration, also passing the configuration parameters
DataSet<Vertex<Long, HashSet<Long>>> result =
graph.runScatterGatherIteration(
new Messenger(), new VertexUpdater(), maxIterations, parameters)
.getVertices();
// user-defined functions
public static final class Messenger extends GatherFunction {...}
public static final class VertexUpdater extends ScatterFunction {...}val graph: Graph[Long, HashSet[Long], Double] = ...
// configure the iteration
val parameters = new ScatterGatherConfiguration
// set the messaging direction
parameters.setDirection(EdgeDirection.IN)
// run the scatter-gather iteration, also passing the configuration parameters
val result = graph.runScatterGatherIteration(new Messenger, new VertexUpdater, maxIterations, parameters)
.getVertices
// user-defined functions
final class Messenger extends ScatterFunction {...}
final class VertexUpdater extends GatherFunction {...}Gather-Sum-Apply Iterations
Like in the scatter-gather model, Gather-Sum-Apply also proceeds in synchronized iterative steps, called supersteps. Each superstep consists of the following three phases:
- Gather: a user-defined function is invoked in parallel on the edges and neighbors of each vertex, producing a partial value.
- Sum: the partial values produced in the Gather phase are aggregated to a single value, using a user-defined reducer.
- Apply: each vertex value is updated by applying a function on the current value and the aggregated value produced by the Sum phase.
Let us consider computing Single-Source-Shortest-Paths with GSA on the following graph and let vertex 1 be the source. During the Gather phase, we calculate the new candidate distances, by adding each vertex value with the edge weight. In Sum, the candidate distances are grouped by vertex ID and the minimum distance is chosen. In Apply, the newly calculated distance is compared to the current vertex value and the minimum of the two is assigned as the new value of the vertex.
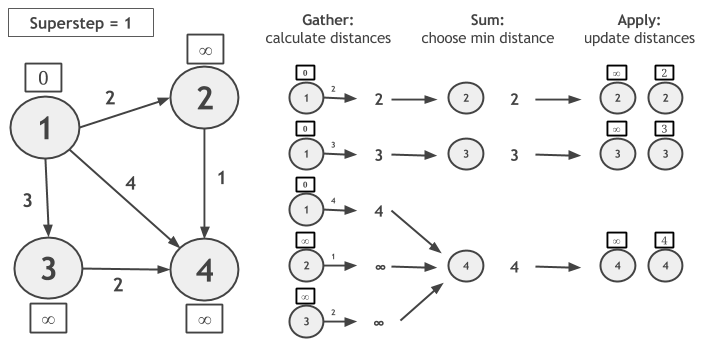
Notice that, if a vertex does not change its value during a superstep, it will not calculate candidate distance during the next superstep. The algorithm converges when no vertex changes value.
To implement this example in Gelly GSA, the user only needs to call the runGatherSumApplyIteration method on the input graph and provide the GatherFunction, SumFunction and ApplyFunction UDFs. Iteration synchronization, grouping, value updates and convergence are handled by the system:
// read the input graph
Graph<Long, Double, Double> graph = ...
// define the maximum number of iterations
int maxIterations = 10;
// Execute the GSA iteration
Graph<Long, Double, Double> result = graph.runGatherSumApplyIteration(
new CalculateDistances(), new ChooseMinDistance(), new UpdateDistance(), maxIterations);
// Extract the vertices as the result
DataSet<Vertex<Long, Double>> singleSourceShortestPaths = result.getVertices();
// - - - UDFs - - - //
// Gather
private static final class CalculateDistances extends GatherFunction<Double, Double, Double> {
public Double gather(Neighbor<Double, Double> neighbor) {
return neighbor.getNeighborValue() + neighbor.getEdgeValue();
}
}
// Sum
private static final class ChooseMinDistance extends SumFunction<Double, Double, Double> {
public Double sum(Double newValue, Double currentValue) {
return Math.min(newValue, currentValue);
}
}
// Apply
private static final class UpdateDistance extends ApplyFunction<Long, Double, Double> {
public void apply(Double newDistance, Double oldDistance) {
if (newDistance < oldDistance) {
setResult(newDistance);
}
}
}// read the input graph
val graph: Graph[Long, Double, Double] = ...
// define the maximum number of iterations
val maxIterations = 10
// Execute the GSA iteration
val result = graph.runGatherSumApplyIteration(new CalculateDistances, new ChooseMinDistance, new UpdateDistance, maxIterations)
// Extract the vertices as the result
val singleSourceShortestPaths = result.getVertices
// - - - UDFs - - - //
// Gather
final class CalculateDistances extends GatherFunction[Double, Double, Double] {
override def gather(neighbor: Neighbor[Double, Double]): Double = {
neighbor.getNeighborValue + neighbor.getEdgeValue
}
}
// Sum
final class ChooseMinDistance extends SumFunction[Double, Double, Double] {
override def sum(newValue: Double, currentValue: Double): Double = {
Math.min(newValue, currentValue)
}
}
// Apply
final class UpdateDistance extends ApplyFunction[Long, Double, Double] {
override def apply(newDistance: Double, oldDistance: Double) = {
if (newDistance < oldDistance) {
setResult(newDistance)
}
}
}Note that gather takes a Neighbor type as an argument. This is a convenience type which simply wraps a vertex with its neighboring edge.
For more examples of how to implement algorithms with the Gather-Sum-Apply model, check the GSAPageRank and GSAConnectedComponents library methods of Gelly.
Configuring a Gather-Sum-Apply Iteration
A GSA iteration can be configured using a GSAConfiguration object.
Currently, the following parameters can be specified:
-
Name: The name for the GSA iteration. The name is displayed in logs and messages and can be specified using the
setName()method. -
Parallelism: The parallelism for the iteration. It can be set using the
setParallelism()method. -
Solution set in unmanaged memory: Defines whether the solution set is kept in managed memory (Flink’s internal way of keeping objects in serialized form) or as a simple object map. By default, the solution set runs in managed memory. This property can be set using the
setSolutionSetUnmanagedMemory()method. -
Aggregators: Iteration aggregators can be registered using the
registerAggregator()method. An iteration aggregator combines all aggregates globally once per superstep and makes them available in the next superstep. Registered aggregators can be accessed inside the user-definedGatherFunction,SumFunctionandApplyFunction. -
Broadcast Variables: DataSets can be added as Broadcast Variables to the
GatherFunction,SumFunctionandApplyFunction, using the methodsaddBroadcastSetForGatherFunction(),addBroadcastSetForSumFunction()andaddBroadcastSetForApplyFunctionmethods, respectively. -
Number of Vertices: Accessing the total number of vertices within the iteration. This property can be set using the
setOptNumVertices()method. The number of vertices can then be accessed in the gather, sum and/or apply functions by using thegetNumberOfVertices()method. If the option is not set in the configuration, this method will return -1. -
Neighbor Direction: By default values are gathered from the out neighbors of the Vertex. This can be modified using the
setDirection()method.
The following example illustrates the usage of the number of vertices option.
Graph<Long, Double, Double> graph = ...
// configure the iteration
GSAConfiguration parameters = new GSAConfiguration();
// set the number of vertices option to true
parameters.setOptNumVertices(true);
// run the gather-sum-apply iteration, also passing the configuration parameters
Graph<Long, Long, Long> result = graph.runGatherSumApplyIteration(
new Gather(), new Sum(), new Apply(),
maxIterations, parameters);
// user-defined functions
public static final class Gather {
...
// get the number of vertices
long numVertices = getNumberOfVertices();
...
}
public static final class Sum {
...
// get the number of vertices
long numVertices = getNumberOfVertices();
...
}
public static final class Apply {
...
// get the number of vertices
long numVertices = getNumberOfVertices();
...
}val graph: Graph[Long, Double, Double] = ...
// configure the iteration
val parameters = new GSAConfiguration
// set the number of vertices option to true
parameters.setOptNumVertices(true)
// run the gather-sum-apply iteration, also passing the configuration parameters
val result = graph.runGatherSumApplyIteration(new Gather, new Sum, new Apply, maxIterations, parameters)
// user-defined functions
final class Gather {
...
// get the number of vertices
val numVertices = getNumberOfVertices
...
}
final class Sum {
...
// get the number of vertices
val numVertices = getNumberOfVertices
...
}
final class Apply {
...
// get the number of vertices
val numVertices = getNumberOfVertices
...
}The following example illustrates the usage of the edge direction option.
Graph<Long, HashSet<Long>, Double> graph = ...
// configure the iteration
GSAConfiguration parameters = new GSAConfiguration();
// set the messaging direction
parameters.setDirection(EdgeDirection.IN);
// run the gather-sum-apply iteration, also passing the configuration parameters
DataSet<Vertex<Long, HashSet<Long>>> result =
graph.runGatherSumApplyIteration(
new Gather(), new Sum(), new Apply(), maxIterations, parameters)
.getVertices();val graph: Graph[Long, HashSet[Long], Double] = ...
// configure the iteration
val parameters = new GSAConfiguration
// set the messaging direction
parameters.setDirection(EdgeDirection.IN)
// run the gather-sum-apply iteration, also passing the configuration parameters
val result = graph.runGatherSumApplyIteration(new Gather, new Sum, new Apply, maxIterations, parameters)
.getVertices()Iteration Abstractions Comparison
Although the three iteration abstractions in Gelly seem quite similar, understanding their differences can lead to more performant and maintainable programs. Among the three, the vertex-centric model is the most general model and supports arbitrary computation and messaging for each vertex. In the scatter-gather model, the logic of producing messages is decoupled from the logic of updating vertex values. Thus, programs written using scatter-gather are sometimes easier to follow and maintain. Separating the messaging phase from the vertex value update logic not only makes some programs easier to follow but might also have a positive impact on performance. Scatter-gather implementations typically have lower memory requirements, because concurrent access to the inbox (messages received) and outbox (messages to send) data structures is not required. However, this characteristic also limits expressiveness and makes some computation patterns non-intuitive. Naturally, if an algorithm requires a vertex to concurrently access its inbox and outbox, then the expression of this algorithm in scatter-gather might be problematic. Strongly Connected Components and Approximate Maximum Weight Matching are examples of such graph algorithms. A direct consequence of this restriction is that vertices cannot generate messages and update their states in the same phase. Thus, deciding whether to propagate a message based on its content would require storing it in the vertex value, so that the gather phase has access to it, in the following iteration step. Similarly, if the vertex update logic includes computation over the values of the neighboring edges, these have to be included inside a special message passed from the scatter to the gather phase. Such workarounds often lead to higher memory requirements and non-elegant, hard to understand algorithm implementations.
Gather-sum-apply iterations are also quite similar to scatter-gather iterations. In fact, any algorithm which can be expressed as a GSA iteration can also be written in the scatter-gather model. The messaging phase of the scatter-gather model is equivalent to the Gather and Sum steps of GSA: Gather can be seen as the phase where the messages are produced and Sum as the phase where they are routed to the target vertex. Similarly, the value update phase corresponds to the Apply step.
The main difference between the two implementations is that the Gather phase of GSA parallelizes the computation over the edges, while the messaging phase distributes the computation over the vertices. Using the SSSP examples above, we see that in the first superstep of the scatter-gather case, vertices 1, 2 and 3 produce messages in parallel. Vertex 1 produces 3 messages, while vertices 2 and 3 produce one message each. In the GSA case on the other hand, the computation is parallelized over the edges: the three candidate distance values of vertex 1 are produced in parallel. Thus, if the Gather step contains “heavy” computation, it might be a better idea to use GSA and spread out the computation, instead of burdening a single vertex. Another case when parallelizing over the edges might prove to be more efficient is when the input graph is skewed (some vertices have a lot more neighbors than others).
Another difference between the two implementations is that the scatter-gather implementation uses a coGroup operator internally, while GSA uses a reduce. Therefore, if the function that combines neighbor values (messages) requires the whole group of values for the computation, scatter-gather should be used. If the update function is associative and commutative, then the GSA’s reducer is expected to give a more efficient implementation, as it can make use of a combiner.
Another thing to note is that GSA works strictly on neighborhoods, while in the vertex-centric and scatter-gather models, a vertex can send a message to any vertex, given that it knows its vertex ID, regardless of whether it is a neighbor. Finally, in Gelly’s scatter-gather implementation, one can choose the messaging direction, i.e. the direction in which updates propagate. GSA does not support this yet, so each vertex will be updated based on the values of its in-neighbors only.
The main differences among the Gelly iteration models are shown in the table below.
| Iteration Model | Update Function | Update Logic | Communication Scope | Communication Logic |
|---|---|---|---|---|
| Vertex-Centric | arbitrary | arbitrary | any vertex | arbitrary |
| Scatter-Gather | arbitrary | based on received messages | any vertex | based on vertex state |
| Gather-Sum-Apply | associative and commutative | based on neighbors' values | neighborhood | based on vertex state |