![]() v1.4
v1.4
- Home
- Concepts
- Quickstart
- Examples
- Project Setup
- Application Development
- Deployment & Operations
- Debugging & Monitoring
- Internals
- Javadocs
- Project Page
- Internals
- Component Stack
Component Stack
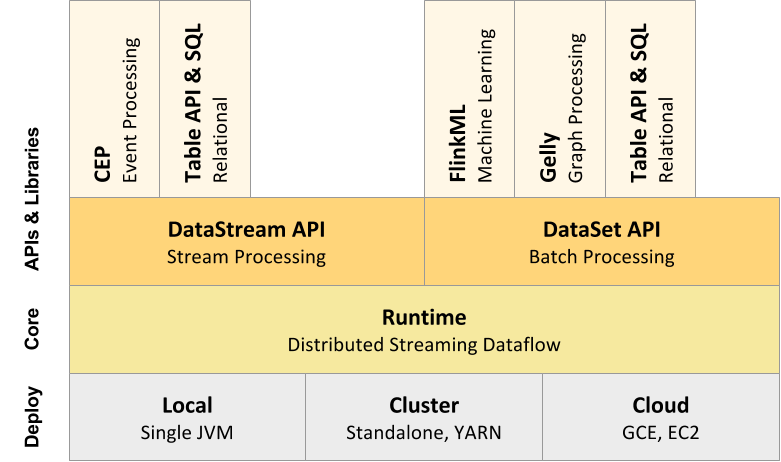
As a software stack, Flink is a layered system. The different layers of the stack build on top of each other and raise the abstraction level of the program representations they accept:
-
The runtime layer receives a program in the form of a JobGraph. A JobGraph is a generic parallel data flow with arbitrary tasks that consume and produce data streams.
-
Both the DataStream API and the DataSet API generate JobGraphs through separate compilation processes. The DataSet API uses an optimizer to determine the optimal plan for the program, while the DataStream API uses a stream builder.
-
The JobGraph is executed according to a variety of deployment options available in Flink (e.g., local, remote, YARN, etc)
-
Libraries and APIs that are bundled with Flink generate DataSet or DataStream API programs. These are Table for queries on logical tables, FlinkML for Machine Learning, and Gelly for graph processing.
You can click on the components in the figure to learn more.